## 참고사항 ##
빅데이터나 하둡 관련 전문가가 아니기 때문에 일부 부족한 내용이 있을 수 있습니다.
셋팅과 기본적인 사용 외에, 하둡과 관련 생태계 운영의 트러블 슈팅은 잘 모릅니다.
오픈소스 특성상 직접 조사하고 해결해야 하는 부분이 많습니다. 기본 셋팅 관련해서 참고만 부탁 드립니다.
업로드한 데이터를 탐색하기 위해 데이터를 열어서 일부 레코드를 확인한다.
Zeppelin을 설정하는 방법은 다음 포스팅을 참고한다.
Zeppelin 설정하고 노트북 생성하기
## 참고사항 ## 빅데이터나 하둡 관련 전문가가 아니기 때문에 일부 부족한 내용이 있을 수 있습니다. 셋팅과 기본적인 사용 외에, 하둡과 관련 생태계 운영의 트러블 슈팅은 잘 모릅니다. 오픈소
www.bearpooh.com
Zeppelin에서 데이터 탐색부터 데이터 변환, 가공은 Spark 코드를 작성해야 하므로 Zeppelin의 범위를 벗어난다.
Spark에 대한 자세한 내용은 다음 도서를 참고한다.
실제 Spark 개발에 참여한 개발자들이 집필한 도서로 Spark 2.3.0 버전 기준이다.
스파크 완벽 가이드 - YES24
스파크 창시자가 알려주는 스파크 활용과 배포, 유지 보수의 모든 것 오픈소스 클러스터 컴퓨팅 프레임워크인 스파크의 창시자가 쓴 스파크에 대한 종합 안내서이다. 스파크 사용법부터 배포,
www.yes24.com
Spark 2.3.0의 기술 문서는 다음을 참고한다. 최신 버전은 URL의 2.3.0을 latest로 변경한다.
https://spark.apache.org/docs/2.3.0/index.html
Overview - Spark 2.3.0 Documentation
Spark Overview Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools
spark.apache.org
기본적으로 Spark은 Java, Scala, Python, R 등의 언어를 지원하지만 Spark에서 Native로 지원하는 Scala 언어를 기준으로 설명한다.
함수 기반 언어인 Scala의 문법을 사용하지만, Scala 문법을 Spark에 맞도록 최적화 했기 때문에 Spark-Scala라고 부르기도 한다.
즉, Spark (Zeppelin 포함) 데이터 분석을 위해서는 Scala 언어에 대한 이해도 일부 필요하다.
Scala 언어 관련 자세한 내용은 다음 도서를 참고한다.
Programming in Scala 4/e - YES24
스칼라는 여러 함수 언어적 기법과 객체지향 기법이 어우러져 루비나 파이썬 같은 동적 언어 못지않게 간결하면서 풍부한 표현력을 가진 언어다. 스칼라는 빅데이터나 머신러닝 등의 최첨단 분
www.yes24.com
Spark (특히 Scala)은 기본적으로 . 을 사용하여 API를 Pipeline으로 사용한다. (Python과 유사)
Scala 언어 특성상 각 API 역시 모두 함수이며, 해당 객체(함수)가 내장하고 있는 변수나 함수만 사용 가능하다.
Spark은 데이터를 DataFrame과 RDD 형태로 처리할 수 있는데, DataFrame의 경우 SQL과 문법이 비슷하다.
자세한 사항은 아래 문서를 참고한다.
Spark SQL and DataFrames - Spark 3.1.2 Documentation
spark.apache.org
데이터 변환과 가공은 무궁무진하므로 위에 언급한 자료들을 참고하여 다양한 시도를 해볼 것을 권장한다.
아래는 기본적인 사항 몇 가지만 다룬다.
데이터 파일 열기
CSV 파일을 열기 위해서는 다음과 같은 코드를 작성한다.
// HDP Sandbox의 경우 하둡 경로를 지정한다.
val total = spark.read.option("header", "true").csv("/test")
// Zeppelin Docker의 경우 컨테이너 내부 경로를 지정한다.
val total = spark.read.option("header", "true").csv("/data/test_data")
파일명까지 지정하면 특정 파일을 열 수 있고, 파일이 위치하는 폴더를 지정하면 해당 폴더 내부의 전체 파일을 읽을 수 있다.

단, 데이터 파일들의 스키마가 모두 동일하거나 대부분 일치해야 한다.
대부분의 컬럼이 일치하고 몇개만 다를 경우 스키마를 통합해서 읽지만, 완전히 다를 경우 레코드가 많은 데이터만 읽힌다.
데이터 스키마 확인
데이터의 컬럼 이름과 데이터 타입을 확인하기 위해서는 다음과 같은 코드를 작성한다.
// 데이터 스키마 확인
total.printSchema
다음과 같이 컬럼명과 데이터 타입을 출력해준다.

컬럼의 데이터 타입 추론
모든 컬럼이 string 타입으로 되어 있는데, inferSchema 옵션을 지정하면 Spark이 알아서 컬럼의 데이터 타입을 추론한다.
// Zeppelin Docker의 경우 컨테이너 내부 경로를 지정한다.
val total = spark.read.option("header", "true").option("inferSchema", "true")
.csv("/data/test_data")
total.printSchema
다음과 같이 각 컬럼의 실제 값에 맞는 데이터 타입으로 변환 된 것을 확인할 수 있다.

데이터 전체 레코드 개수 확인
데이터에 포함 된 전체 레코드 개수를 확인하기 위해서는 다음과 같은 코드를 작성한다.
// 전체 레코드 개수 확인
total.count
다음과 같이 해당 데이터의 전체 레코드를 출력한다.

데이터의 일부 레코드 확인
데이터를 잘 읽었는지 확인하기 위해서는 실제 레코드의 일부를 직접 보는 것이 중요하다.
// 긴 컬럼은 축약하고 20개 레코드만 출력 (기본 설정이 20개)
total.show
// 긴 컬럼을 그대로 출력하고 20개 레코드만 출력
total.show(false)
// 긴 컬럼은 축약하고 5개 레코드만 출력
total.show(5)
// 긴 컬럼을 그대로 출력하고 5개 레코드만 출력
total.show(5, false)
예제 코드 중 마지막 코드를 실행한 결과는 다음과 같다.

컬럼 파티셔닝 기능 활용
컬럼 파티셔닝 기능을 활용하면 스키마가 동일한데 데이터 파일이 많은 경우 효과적으로 읽고 관리할 수 있다.
폴더명을 Key=Value 형태로 지정하면 데이터를 읽을 수 있다.

다음과 같이 Key=Value 폴더의 상위 경로를 지정하여 데이터를 읽는다.
val total = spark.read.option("header", "true")
.option("inferSchema", "true").csv("/data/test")
total.printSchema
하단에 country 컬럼이 추가 된 것을 확인할 수 있다.

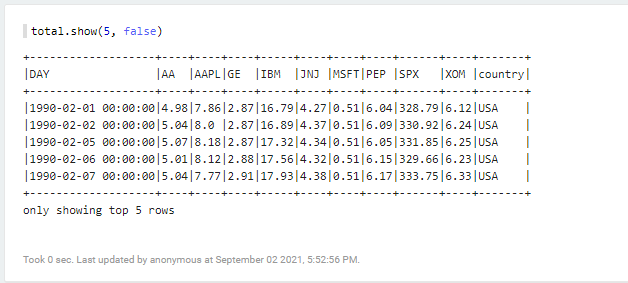
show 명령을 사용하여 데이터를 출력해서 실제 레코드를 확인한다.
total.show(5, false)
Key=Value 폴더명의 Key가 컬럼명으로, Value가 값으로 입력 된 것을 확인할 수 있다.
데이터 다루기
데이터를 읽었다면 원하는 목적에 맞게 데이터를 가공해야 한다.
컬럼명 변경하기
컬럼 이름을 변경하고자 하는 경우는 withColumnRenamed를 사용한다.
// 컬럼명을 AAPL에서 APPLE로 변경하기
total.withColumnRenamed("AAPL", "APPLE").show(5)
다음과 같이 컬럼명이 변경 된 것을 확인할 수 있다.

컬럼 추가하기
컬럼을 추가하기 위해서는 withColum을 사용한다.
고정값으로 채우기
고정 값으로 채우려면 lit(원하는값) 형태를 사용한다.
// SEC 컬럼을 추가하고 100 값으로 채우기
total.withColumn("SEC", lit(100))
컬럼의 마지막에 지정한 컬럼과 값이 추가된 것을 확인할 수 있다.

다른 컬럼의 값을 변경하여 채우기
다른 컬럼의 값을 변경하려면 col(컬럼명) 형태로 지정 후 연산을 지정한다.
// SEC 컬럼을 추가하고 MSFT 컬럼 값에 10을 곱해 추가하기
total.withColumn("SEC", col("MSFT")*10).show(5)
컬럼의 마지막에 지정한 컬럼과 값이 추가된 것을 확인할 수 있다.

특정 컬럼 선택하기
특정 컬럼만 선택하기 위해서는 SQL과 유사하게 select를 사용한다.
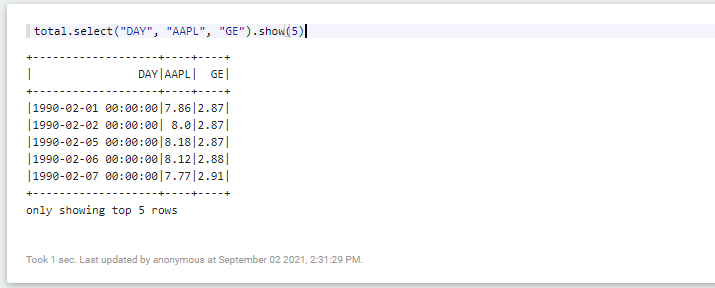
// DAY, AAPL, GE 컬럼 선택하기
total.select("DAY", "AAPL", "GE").show(5)
다음과 같이 선택한 컬럼명만 출력되는 것을 확인할 수 있다.
조회 결과에 조건 지정하기
조회 결과에 조건을 지정하여 필터링하고 싶은 경우에는 SQL과 유사하게 where를 사용한다.
// AAPL 값이 7보다 작은 경우만 조회
total.select("DAY", "AAPL", "GE").where(col("AAPL") < 7).show(5)
다음과 같이 AAPL이 7보다 작은 경우만 출력되는 것을 확인할 수 있다.

컬럼의 값 연산하기
특정 컬럼의 합계, 평균, 최대값, 최소값 구하기
특정 컬럼의 합계, 평균, 최대값, 최소값은 다음과 같이 구할 수 있다.
컬럼명을 지정할때 가급적 col(컬럼명) 형태로 지정할 것을 권장한다. (물론 생략해도 된다.)
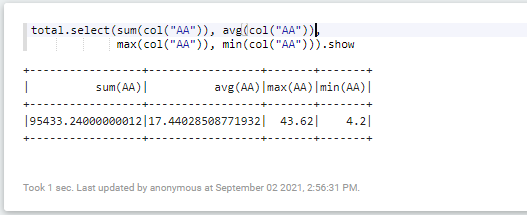
// AA 컬럼의 합계 구하기
total.select(sum(col("AA"))).show
// AA 컬럼의 평균 구하기
total.select(avg(col("AA"))).show
// AA 컬럼의 최대값 구하기
total.select(max(col("AA"))).show
// AA 컬럼의 최소값 구하기
total.select(min(col("AA"))).show
다음과 같이 특정 컬럼의 합계, 평균, 최대값, 최소값을 구할 수 있다.
as 함수를 사용하면 결과 컬럼의 이름을 변경할 수 있다.

컬럼 간의 값 연산
여러 컬럼의 값을 사용하여 연산할 수 있다.
// AA 컬럼과 AAPL 컬럼의 값을 더하기
total.select(col("AA") + col("AAPL")).show(5)
다음과 같이 컬럼간 값 연산이 가능하며, as 함수로 결과 컬럼에 대한 이름 변경도 가능하다.

또한 연산 결과에 대한 합계, 평균, 최대, 최소 값을 구할 수 있다.
// AA 컬럼과 AAPL 컬럼의 값을 더하고 최대값 출력하기
total.select(max(col("AA") + col("AAPL"))).show(5)
다음과 같이 두 컬럼의 값을 구하고 최대 값을 추출할 수 있고, as 함수로 결과 컬럼에 대한 이름 변경도 가능하다.

데이터 시각화
Zeppelin에 자체적으로 시각화 도구를 제공한다.
Table, Bar Chart, Pie Chart, Area Chart, Line Chart, Scatter Chart를 제공하며, Table과 Bar Chart에 대해서 확인해본다.
코드 작성
시각화 하기 위한 데이터를 추출하고 시각화 도구로 전달하는 코드를 작성한다.
시각화 하려는 DataFrame을 생성하고 z.show에 전달한다.
// DAY, AAPL, GE 컬럼을 선택하고 100개 레코드만 사용한다.
// DAY 컬럼은 to_date로 연-월-일만 추출하고, DATE로 컬럼명을 변경한다.
val visDf = total.select(to_date(col("DAY")).as("DATE"), col("AAPL"), col("GE"))
.limit(100)
// z.show로 DataFrame을 전달하면 시각화가 가능하다.
z.show(visDf)
Table
위의 코드를 실행하면 기본 설정으로 Table이 출력된다.

Table은 다음과 같은 경우에 사용한다.
- 시각화 하려는 값이 제대로 추출되었는지 확인하는 경우
- 간단한 내용이라 시각화 없이 데이터를 보여주는 경우
테이블 상단에 Chart 종류에 대한 아이콘이 있으며, 순서대로 Table, Bar Chart, Pie Chart, Area Chart, Line Chart, Scatter Chart를 의미한다.
Bar Chart
테이블 상단의 Chart 종류에서 두번째를 클릭하면 Bar Chart를 생성할 수 있다.
Zeppelin에서 컬럼을 자동으로 선택해서 그래프를 그려준다.
변경이 필요한 경우 Chart 아이콘 우측의 settings를 클릭한다.

Available Fields 항목이 표시되며, keys, groups, values 항목을 설정하도록 나온다.
- keys - X 축으로 사용할 값을 의미한다.
- values - Y 축으로 사용할 값을 의미한다.
- groups - Y 축에 표시할 값들을 groups를 기준으로 세부 분류를 할 수 있다.
Available Fields의 컬럼명을 클릭하고 드래그앤드롭 (Drag&Drop)으로 keys, groups, values로 옮기면 된다.

아래와 같은 그래프로 시각화 된 것을 확인할 수 있다.
- Grouped - 항목별로 구분 된 그래프로 표현
- Stacked - 누적 그래프로 표현

그래프 공유
시각화 한 그래프는 공유할 수 있다.
우측 상단의 톱니 바퀴를 클릭하고 Link this paragraph를 클릭한다.

다음과 같이 접근 가능한 URL이 생성되며 그래프만 별도의 페이지에 생성된다.
해당 그래프의 URL을 공유하거나 캡쳐하여 사용하면 된다.

환경에 따른 Spark 버전 차이 주의!
HDP Sandbox의 Zeppelin은 Sandbox에 포함 된 Spark을 사용하고, Zeppelin Docker는 내장 된 Spark Intepreter를 사용하기 때문에 Spark 버전이 다르다.
HDP Sandbox의 Zeppelin
Spark은 4040 포트를 사용하므로 다음 주소로 접속하면 Spark에 접속할 수 있다.
해당 주소로 접속하면 8088 포트로 리다이렉트 되면서 Spark 관련 정보가 표시된다.
Spark의 버전은 2.3.1로 확인된다.
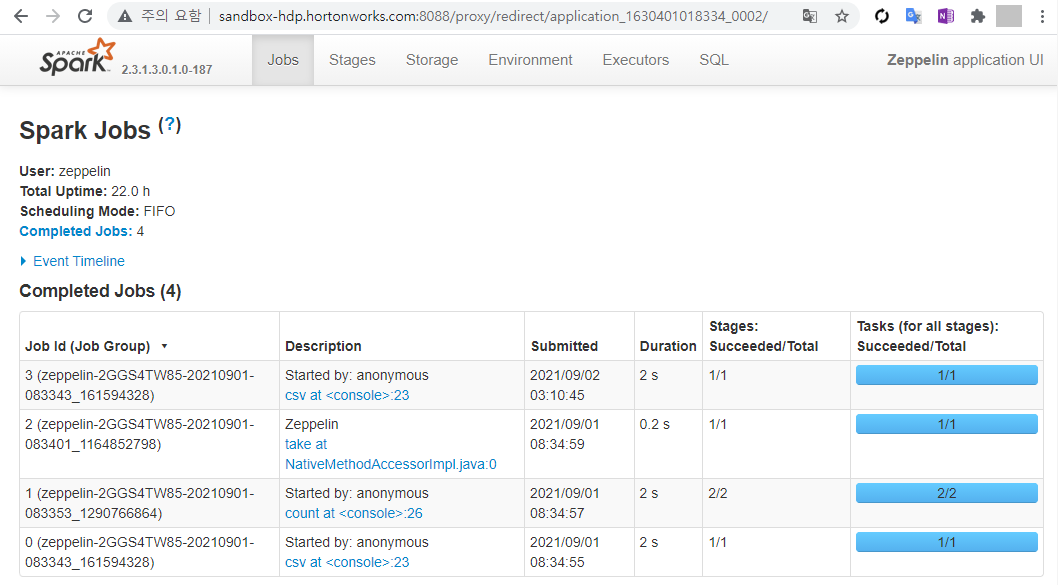
참고로 8088 포트는 Hadoop의 클러스터들을 관리하는 Yarn 서비스가 사용하는 포트이다.
해당 포트로 접속해보면 Zeppelin 서비스가 3개의 컨테이너를 사용하면서 실행 중인 것을 확인할 수 있다.

Zeppelin Docker
Zepplein Docker의 컨테이너를 생성할 때 포트를 9997->8080만 개방했으므로 Spark 포트인 4040 포트 개방도 추가해야 한다.
컨테이너 종료 후 다음과 같이 4040 포트 개방도 추가해서 컨테이너를 재생성한다.
4040 포트는 HDP Sandbox가 사용중이어서 9998 포트를 이용하여 연결했다.
# Zeppelin 컨테이너 종료
$ docker stop zeppelin
# 4040 포트 추가하여 컨테이너 재실행
# Zeppelin Docker 이미지 Pull과 컨테이너 생성
$ docker run -d -p 9997:8080 -p 9998:4040 --rm \
-v ~/zeppelin_logs:/logs \
-v ~/zeppelin_notebook:/zeppelin/notebook \
-v ~/zeppelin_data:/data \
-e ZEPPELIN_LOG_DIR=/logs \
--add-host dl.bintray.com:127.0.0.1 \ # 폐쇄망 또는 사설 저장소를 사용하는 경우 추가
--add-host repo1.maven.org:127.0.0.1 \ # 폐쇄망 또는 사설 저장소를 사용하는 경우 추가
--name zeppelin \
Docker저장소URL:포트/apache/zeppelin:0.8.1 # ex. docker.test.com:5000/apache/zeppelin:0.8.1
컨테이너 생성 후 아래 주소로 접속한다.
- http://localhost:9998
- Docker 컨테이너를 생성할 때 9998이 아닌 다른 포트를 지정한 경우 해당 포트를 사용한다.
Spark 버전이 2.2.1인 것을 확인할 수 있다.

Spark은 Major 버전뿐 아니라 Minor 버전이 다른 경우에도 지원하지 않거나 스펙이 변경 된 API 들이 있으므로 버전 확인을 반드시 해야 한다.
Spark Job 분석
Spark Jobs의 Decription 컬럼의 링크를 클릭하면 각 Job의 세부 작업인 Stage 목록을 확인할 수 있다.

Stage의 Decription 컬럼의 링크를 클릭하면 각 Stage의 세부 실행 내역을 확인할 수 있다.

실행 중 오류가 발생하거나 이상이 있는 경우 이 부분을 잘 살펴보면 문제의 원인을 찾을 수 있다.
이 부분은 Spark의 모니터링과 최적화에 해당하는 부분이며, 다음 도서와 공식 문서를 참고하는 것을 권장한다.
스파크 완벽 가이드 - YES24
스파크 창시자가 알려주는 스파크 활용과 배포, 유지 보수의 모든 것 오픈소스 클러스터 컴퓨팅 프레임워크인 스파크의 창시자가 쓴 스파크에 대한 종합 안내서이다. 스파크 사용법부터 배포,
www.yes24.com
Overview - Spark 2.3.0 Documentation
Spark Overview Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools
spark.apache.org
Study and Try
기본적인 사항은 이 정도로 마무리한다.
DataFrame과 RDD를 통해 데이터 변환 가공은 무궁무진하게 시도할 수 있으므로, 더 많이 공부하고 다양한 시도를 해볼 것을 권한다.
'::: 데이터 분석 :::' 카테고리의 다른 글
| [Ambari 1] Apache Ambari 소개 (2) | 2023.03.03 |
|---|---|
| Zeppelin 0.10.1 버전 Docker로 사용하기 (0) | 2022.08.29 |
| Zeppelin 설정하고 노트북 생성하기 (0) | 2021.10.21 |
| HDP Sandbox에서 Superset 사용하기 (0) | 2021.10.18 |
| HDP Sandbox 3.0.1 사용 관련 참고 사항 (0) | 2021.10.14 |