## 참고사항 ##
빅데이터나 하둡 관련 전문가가 아니기 때문에 일부 부족한 내용이 있을 수 있습니다.
셋팅과 기본적인 사용 외에, 하둡과 관련 생태계 운영의 트러블 슈팅은 잘 모릅니다.
오픈소스 특성상 직접 조사하고 해결해야 하는 부분이 많습니다. 기본 셋팅 관련해서 참고만 부탁 드립니다.
Zeppelin은 Spark 기반의 데이터 분석을 위한 인터프리터 환경을 제공한다.
파이썬의 데이터 분석 도구인 Jupyter Notebook과 비슷하다.
Zeppelin은 HDP Sandbox에 포함되어 있으며, Docker로 Zeppelin만 독립적으로 사용할 수도 있다.
- HDP Sandbox에 포함 된 Zeppelin은 내부 Hadoop과 Spark을 기반으로 동작한다.
- Zeppelin을 독립적인 Docker로 실행하는 경우 내장 된 Spark 엔진을 기반으로 동작한다.
참고로 Zeppelin은 Spark 뿐 아니라 아래와 같은 인터프리터도 제공한다.
| Cassandra ElasticSearch HDFS Hive |
Livy Markdown Neo4J Postgresql |
R Shell |
그 외에도 다양한 인터프리터를 제공하는데 자세한 내용은 아래 공식 문서를 참고한다.
Apache Zeppelin 0.8.0 Documentation:
What is Apache Zeppelin? Multi-purpose notebook which supports 20+ language backends Data Ingestion Data Discovery Data Analytics Data Visualization & Collaboration
zeppelin.apache.org
Zeppelin을 설정하는 방법과 사용법에 대해 정리한다.
Zeppelin 설정
HDP Sandbox 사용
HDP Sandbox 2.6.5와 3.0.1 버전 모두 Zeppelin을 기본 서비스로 제공한다.
- HDP Sandbox 2.6.5 - Zeppelin 0.7.3 버전
- HDP Sandbox 3.0.1 - Zeppelin 0.8.0 버전
HDP Sandbox 설정은 다음 포스팅을 참고한다.
HDP Sandbox 소개와 Docker 셋팅 파일 다운로드
참고사항 본 글은 2018년에 기술 조사를 진행하면서 확인한 내용으로, 최신 상황에 맞게 업데이트 하였으나 일부 부족한 내용이 있을 수 있습니다. 빅데이터나 하둡 관련 전문가가 아니기 때문에
www.bearpooh.com
HDP Sandbox 2.6.5 Docker 설정과 Ambari 로그인하기
참고사항 본 글은 2018년에 기술 조사를 진행하면서 확인한 내용으로, 최신 상황에 맞게 업데이트 하였으나 일부 부족한 내용이 있을 수 있습니다. 빅데이터나 하둡 관련 전문가가 아니기 때문에
www.bearpooh.com
HDP Sandbox 3.0.1 Docker 이미지로 Ambari 로그인하기
## 참고사항 ## 빅데이터나 하둡 관련 전문가가 아니기 때문에 일부 부족한 내용이 있을 수 있습니다. 셋팅과 기본적인 사용 외에, 하둡과 관련 생태계 운영의 트러블 슈팅은 잘 모릅니다. 오픈소
www.bearpooh.com
HDP Sandbox 3.0.1 사용 관련 참고 사항
## 참고사항 ## 빅데이터나 하둡 관련 전문가가 아니기 때문에 일부 부족한 내용이 있을 수 있습니다. 셋팅과 기본적인 사용 외에, 하둡과 관련 생태계 운영의 트러블 슈팅은 잘 모릅니다. 오픈소
www.bearpooh.com
아래는 HDP Sandbox 3.0.1 버전을 기준으로 정리한다.
HDP Sandbox 컨테이너를 실행하면 자동 시작 되고, Ambari 좌측의 Zeppelin 항목에 녹색으로 표시된다.

빨간색으로 표시 된 경우 해당 서비스가 정상적인 상태가 아니므로 서비스 재시작을 수행하고 다시 확인한다.
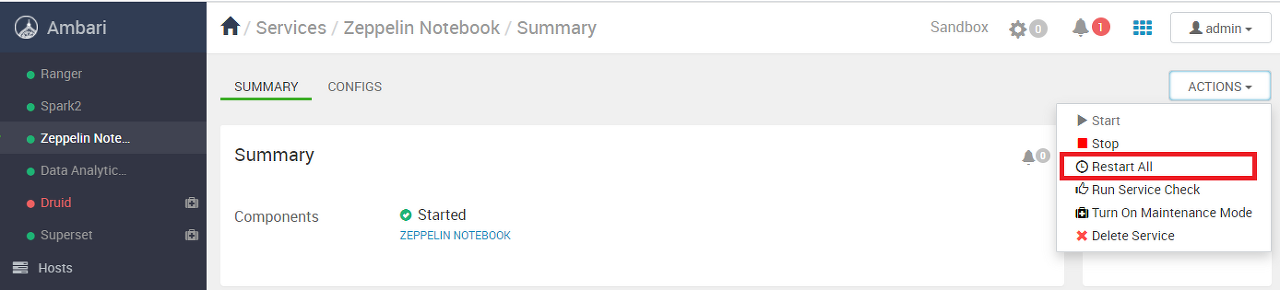
Zeppelin은 9995 포트를 사용하므로 아래 URL을 통해 정상 접근하는지 확인한다.
정상 접속되면 아래와 같은 화면이 나타난다. 우측 상단에 녹색으로 표시되어야 한다.

Docker 사용
HDP Sandbox 설정 없이 Zeppelin만 사용하고자 하는 경우 Zeppelin Docker 이미지를 사용한다.
리눅스/Mac 환경
아래 명령을 실행하면 Zeppelin을 Docker 컨테이너를 생성할 수 있다.
# Zeppelin Docker 이미지 Pull과 컨테이너 생성 $ docker run -p 9997:8080 --rm \ -v ~/zeppelin_logs:/logs \ -v ~/zeppelin_notebook:/zeppelin/notebook \ -v ~/zeppelin_data:/data \ -e ZEPPELIN_LOG_DIR=/logs \ --add-host dl.bintray.com:127.0.0.1 \ # 폐쇄망 또는 사설 저장소를 사용하는 경우 추가 --add-host repo1.maven.org:127.0.0.1 \ # 폐쇄망 또는 사설 저장소를 사용하는 경우 추가 --name zeppelin \ Docker저장소URL:포트/apache/zeppelin:0.8.1 # ex. docker.test.com:5000/apache/zeppelin:0.8.1
세부 설정은 다음과 같다.
| 구분 | 내용 |
| 9997:8080 | 기본 설정인 8080 포트가 HDP Sandbox와 사용하는 포트가 겹쳐 9997로 변경 |
| logs 공유 볼륨 폴더 |
/home/계정명 경로 하위에 zeppelin_logs 폴더를 컨테이너의 /logs 경로와 공유한다. Zeppelin이 실행되면서 생성하는 로그들이 저장된다. |
| notebook 공유 볼륨 폴더 |
/home/계정명 경로 하위에 zeppelin_notebooks 폴더를 컨테이너의 /zeppelin/notebook 경로와 공유한다. Zeppelin에서 생성한 노트북들이 저장된다. |
| data 공유 볼륨 폴더 |
/home/계정명 경로 하위에 zeppelin_data 폴더를 컨테이너의 /data 경로와 공유한다. 사용할 데이터는 호스트의 ~/zeppelin_data 폴더 하위에 저장한다. (ex. ~/zeppelin_data/test) Zeppelin에서 /data의 하위 경로로 지정하여 데이터를 사용한다. (ex. /data/test) |
| Zeppelin 로그 경로 설정 |
Zeppelin 컨테이너에 ZEPPELIN_LOG_DIR 환경 변수를 생성하고 /logs 경로를 지정한다. Host PC와 공유 볼륨 설정이 되어 있어 Host PC의 폴더에 로그가 저장된다. |
| 컨테이너 이름 | --name 옵션으로 zeppelin을 지정했다. 필요한 경우 다른 이름을 부여한다. |
| Docker 이미지 경로 |
Docker저장소URL:포트/apache/zeppelin:0.8.1 을 사용한다. ex. docker.test.com:5000/apache/zeppelin:0.8.1 DockerHub를 사용하는 경우에는 /apache/zeppelin:0.8.1 만 입력한다. |
| add-host 옵션 | 페쇄망이거나 사설 저장소를 사용하는 경우에만 사용한다. 라이브러리를 다운로드 하기 위해 해당 URL로 접속을 시도하면서 진행되지 않는다. |
이후 컨테이너 종료와 재시작은 다음 명령을 실행한다.
# Zeppelin 컨테이너 종료 $ docker stop zeppelin # Zeppelin 컨테이너 시작 $ docker start zeppelin # Zeppelin 컨테이너 삭제 $ docker stop zeppelin $ docker rm zeppelin
Zeppelin은 9997 포트를 사용하므로 아래 URL을 통해 정상 접근하는지 확인한다.
정상 접속되면 아래와 같은 화면이 나타난다. 우측 상단에 녹색으로 표시되어야 한다.

HDP Sandbox에 존재하는 Tutorial 노트북이 없는 것이 특징이다.
윈도우 환경
리눅스 환경의 옵션을 그대로 사용하는 경우 공유 볼륨 경로를 수정해야 한다.
윈도우 10의 Bash가 활성화 된 경우에는 그대로 사용 가능하다.
단, /home/사용자계정 경로로 생성되며 bash 쉘로만 접근 가능하다.
윈도우의 CMD 창에서 실행하고자 하는 경우 공유 볼륨을 다음과 같이 수정한다.
# Zeppelin Docker 이미지 Pull과 컨테이너 생성 $ docker run -p 9997:8080 --rm \ -v "윈도우경로":/logs \ # C:\Users\사용자계정\zeppelin\logs -v "윈도우경로":/zeppelin/notebook \ # C:\Users\사용자계정\zeppelin\notebook -v "윈도우경로"/zeppelin_data:/data \ # # C:\Users\사용자계정\zeppelin\data -e ZEPPELIN_LOG_DIR=/logs \ --add-host dl.bintray.com:127.0.0.1 \ # 폐쇄망 또는 사설 저장소를 사용하는 경우 추가 --add-host repo1.maven.org:127.0.0.1 \ # 폐쇄망 또는 사설 저장소를 사용하는 경우 추가 --name zeppelin \ Docker저장소URL:포트/apache/zeppelin:0.8.1 # ex. docker.test.com:5000/apache/zeppelin:0.8.1
나머지 내용은 리눅스/Mac 환경 항목을 참고한다.
Zeppelin 사용
데이터 준비
Spark은 기본적으로 CSV 외에도 Parquet, ORC 등 컬럼 기반 포맷과 JSON 등의 데이터 파일 포맷도 지원하고, jdbc를 통한 데이터베이스 연결도 가능하다.
또한 S3와 Minio 등 Object 기반 Storage 서비스의 데이터도 읽을 수 있다.
Superset에서 사용했던 CSV 포맷의 예제 데이터를 활용한다.
Superset 관련 내용은 다음 포스팅을 참고한다.
HDP Sandbox에서 Superset 사용하기
## 참고사항 ## 빅데이터나 하둡 관련 전문가가 아니기 때문에 일부 부족한 내용이 있을 수 있습니다. 셋팅과 기본적인 사용 외에, 하둡과 관련 생태계 운영의 트러블 슈팅은 잘 모릅니다. 오픈소
www.bearpooh.com
HDP Sandbox 사용
HDP Sandbox의 경우 아래 포스팅을 참고하여 예제 데이터를 HDFS에 업로드 한다.
HDP Sandbox 3.0.1 사용 관련 참고 사항
## 참고사항 ## 빅데이터나 하둡 관련 전문가가 아니기 때문에 일부 부족한 내용이 있을 수 있습니다. 셋팅과 기본적인 사용 외에, 하둡과 관련 생태계 운영의 트러블 슈팅은 잘 모릅니다. 오픈소
www.bearpooh.com
테스트 데이터는 작은 용량의 CSV 파일 1개이므로 Ambari의 Files View에서 폴더를 생성하고 업로드하면 된다.
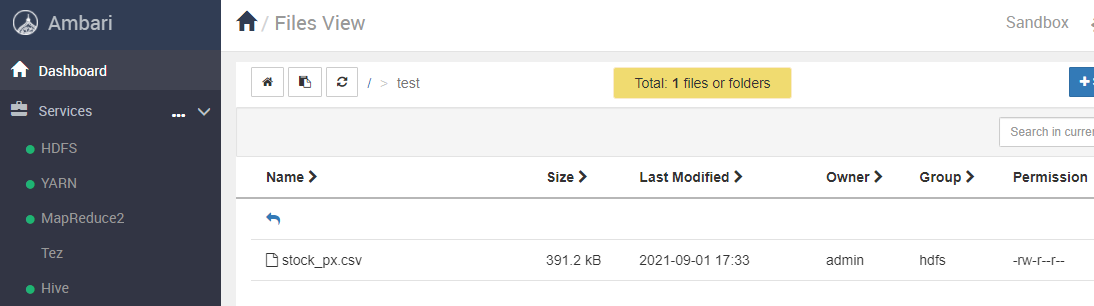
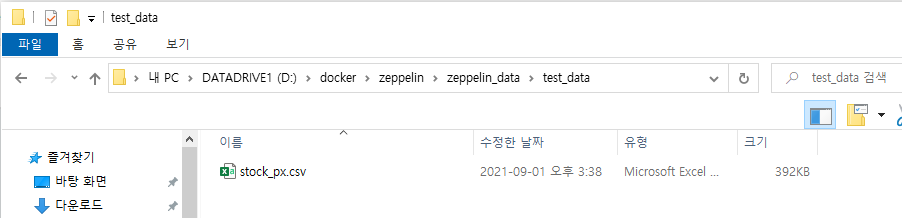
Docker 사용
로컬에서 Docker로 Zeppelin 컨테이너를 생성한 경우 공유 볼륨으로 지정한 data 폴더에 파일을 복사한다.
Zeppelin에서노트북 생성
데이터를 사용하기 위해 Zeppelin에 접속하고 노트북을 생성한다.
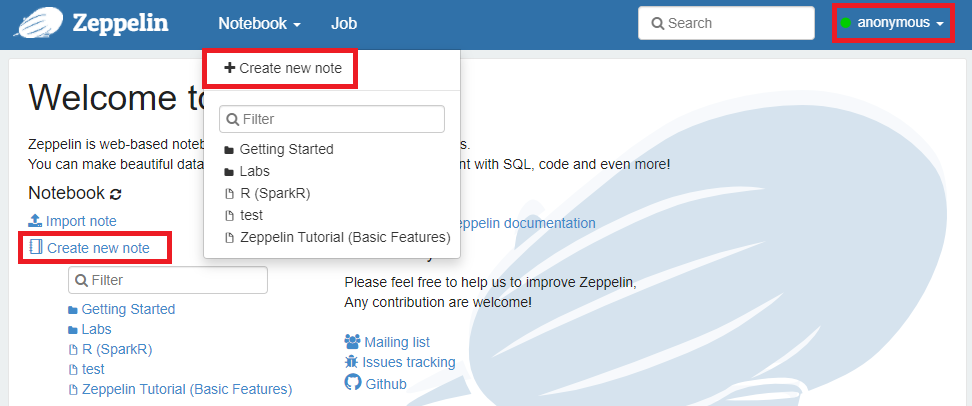
생성하려는 노트북의 이름을 입력하고 Create 버튼을 클릭한다.
노트북 이름은 사용하는 데이터와 분석 목적을 쉽게 이해할 수 있으면 된다.

다음과 같이 노트북이 생성되었다.
Spark 인터프리터 설정 변경
우측 상단의 anonymous를 선택하고 Interpreter를 클릭한다.

다양한 환경의 인터프리터가 존재하는데 스크롤을 아래로 계속 내리면 가장 아래에 Spark이 있다.
edit 버튼을 눌러 필요한 설정을 변경한다.
옵션에 대한 세부 사항은 아래 문서를 참고한다.
Apache Zeppelin 0.8.0 Documentation: Apache Spark Interpreter for Apache Zeppelin
'::: 데이터 분석 :::' 카테고리의 다른 글
| Zeppelin 0.10.1 버전 Docker로 사용하기 (0) | 2022.08.29 |
|---|---|
| Zeppelin에서 데이터 탐색하기 (2) | 2021.10.25 |
| HDP Sandbox에서 Superset 사용하기 (0) | 2021.10.18 |
| HDP Sandbox 3.0.1 사용 관련 참고 사항 (0) | 2021.10.14 |
| HDP Sandbox 3.0.1의 HDFS에 admin, root 계정 권한 추가하기 (0) | 2021.10.11 |