## 참고사항 ##
빅데이터나 하둡 관련 전문가가 아니기 때문에 일부 부족한 내용이 있을 수 있습니다.
셋팅과 기본적인 사용 외에, 하둡과 관련 생태계 운영의 트러블 슈팅은 잘 모릅니다.
오픈소스 특성상 직접 조사하고 해결해야 하는 부분이 많습니다. 기본 셋팅 관련해서 참고만 부탁 드립니다.
HDP Sandbox에서 Superset도 사용 가능하다.
Superset은 에어비앤비에서 오픈소스로 공개한 데이터 분석 도구로 다음과 같은 장점이 있다.
- 다양한 시각화를 제공하여 대시보드 구성이 가능하다.
- SQL을 사용하기 때문에 기존 RDBMS에 익숙한 사용자들이 쉽게 사용할 수 있다.
HDP Sandbox에 대한 소개와 설치 스크립트 다운로드는 다음 포스팅을 참고한다.
HDP Sandbox 소개와 Docker 셋팅 파일 다운로드
참고사항 본 글은 2018년에 기술 조사를 진행하면서 확인한 내용으로, 최신 상황에 맞게 업데이트 하였으나 일부 부족한 내용이 있을 수 있습니다. 빅데이터나 하둡 관련 전문가가 아니기 때문에
www.bearpooh.com
HDP Sandbox 2.6.5 버전을 Docker로 설치하는 방법은 다음 포스팅을 참고한다.
HDP Sandbox 2.6.5 Docker 설정과 Ambari 로그인하기
참고사항 본 글은 2018년에 기술 조사를 진행하면서 확인한 내용으로, 최신 상황에 맞게 업데이트 하였으나 일부 부족한 내용이 있을 수 있습니다. 빅데이터나 하둡 관련 전문가가 아니기 때문에
www.bearpooh.com
HDP Sandbox 3.0.1 버전에 대한 설치와 Amabari 로그인하는 방법은 다음 포스팅을 참고한다.
HDP Sandbox 3.0.1 Docker 이미지로 Ambari 로그인하기
## 참고사항 ## 빅데이터나 하둡 관련 전문가가 아니기 때문에 일부 부족한 내용이 있을 수 있습니다. 셋팅과 기본적인 사용 외에, 하둡과 관련 생태계 운영의 트러블 슈팅은 잘 모릅니다. 오픈소
www.bearpooh.com
HDP Sandbox 사용 관련 참고사항은 다음 포스팅을 참고한다.
HDP Sandbox 3.0.1 사용 관련 참고 사항
## 참고사항 ## 빅데이터나 하둡 관련 전문가가 아니기 때문에 일부 부족한 내용이 있을 수 있습니다. 셋팅과 기본적인 사용 외에, 하둡과 관련 생태계 운영의 트러블 슈팅은 잘 모릅니다. 오픈소
www.bearpooh.com
이번 포스팅에서는 HDP Sandbox의 Superset을 사용하는 방법과 예제를 진행하는 방법을 정리한다.
테스트는 HDP Sandbox 3.0.1을 기준으로 진행한다.
Superset 서비스 활성화
HDP Sandbox를 설치하고 Ambari에 접속하면 좌측 하단에 Superset이 있다.
기본 설정이 Superset 서비스를 사용하지 않는 것으로 되어 있어서 빨간색으로 표시되어 있다. Superset을 클릭한다.

서비스 시작을 위해 우측 상단의 Actions를 클릭하고 Start 버튼을 누른다.
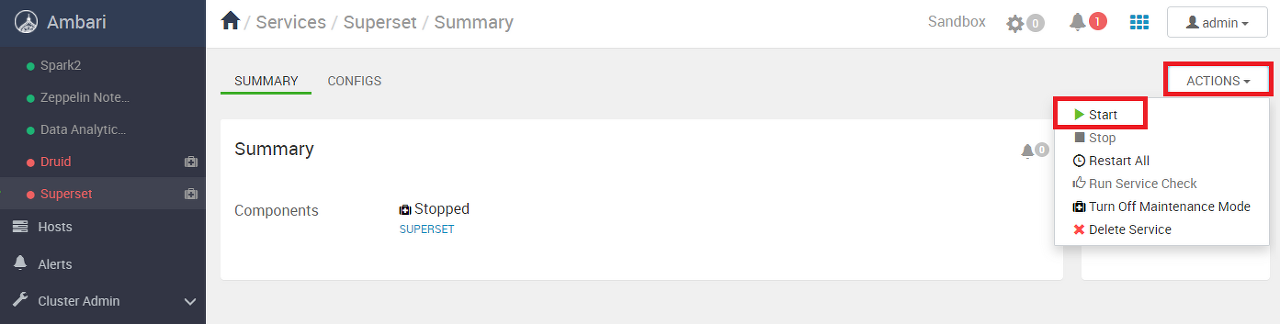
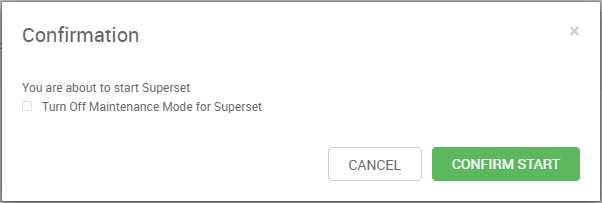
CONFIRM START 버튼을 클릭하면 Superset 서비스가 시작된다.
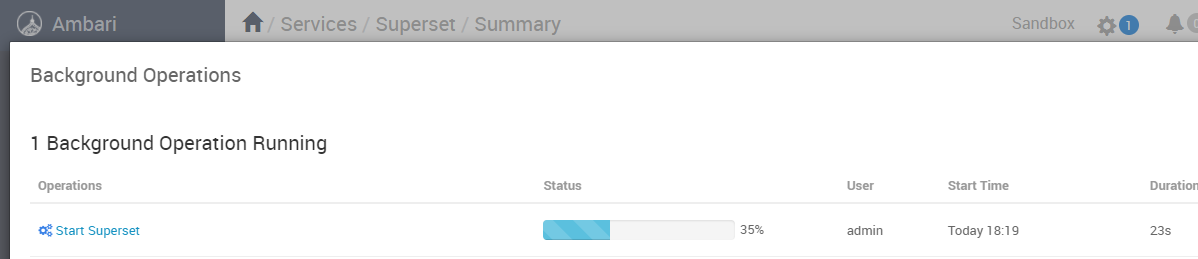
상단의 톱니바퀴를 누르면 서비스 시작 진행상황을 확인할 수 있다.
Superset 접속
서비스 시작이 완료되면 우측 Quick Links의 Superset을 클릭하여 Superset에 접속한다.

또는 아래 URL로도 접속할 수 있다.
http://sandbox-hdp.hortonworks.com:9089/
접속하면 다음과 같은 초기화면을 볼 수 있다.
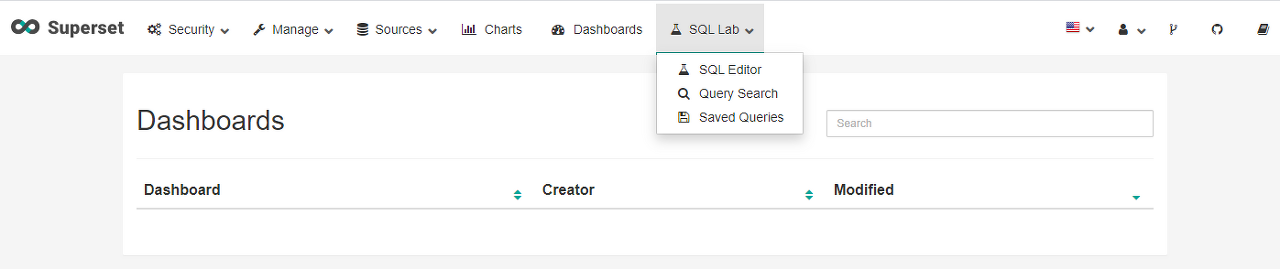
상단 메뉴 우측의 SQL Lab을 선택하고 SQL Editor를 클릭하면 SQL 쿼리 작성이 가능한 UI를 확인할 수 있다.

우측 상단의 미국 국기 옆에 있는 사람을 클릭하고 Profile을 클릭해보면 admin 계정인 것을 확인할 수 있다.
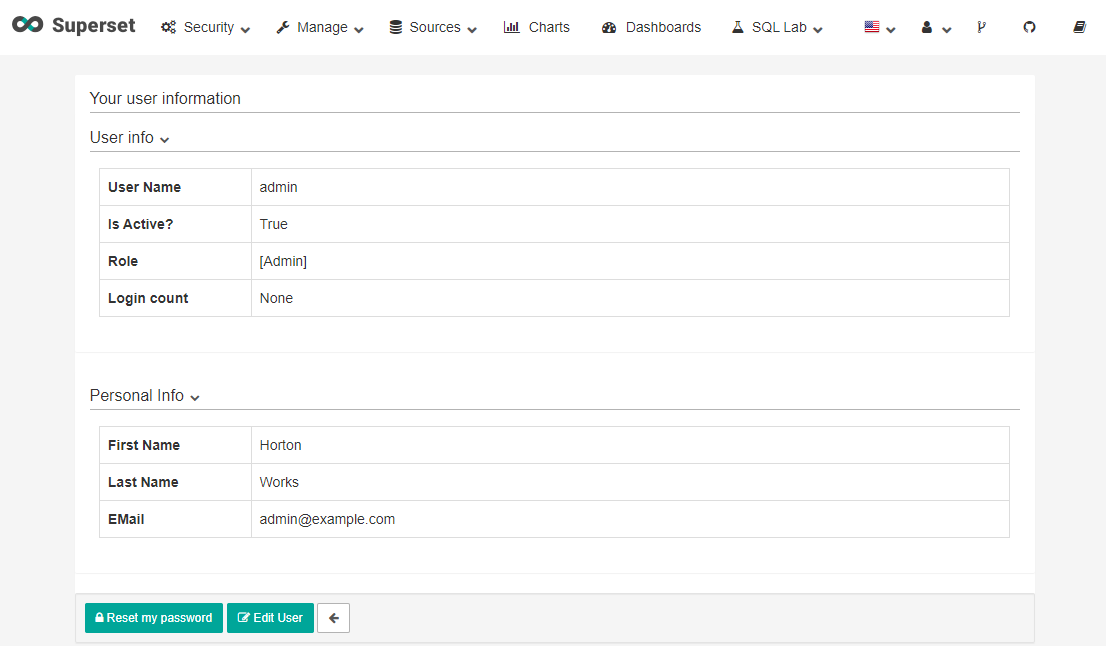
필요한 경우 하단의 Reset my password를 클릭하고 비밀번호를 변경한다.
테스트를 위한 Database 생성
테스트에 사용할 Database를 생성한다.
기본으로 제공되는 main Database는 Superset 관련 된 것이므로, 테스트에 사용할 데이터는 별개의 Database를 생성하여 진행하는 것을 권장한다.
상단의 Databases를 클릭한다.

우측 상단의 +를 클릭한다.
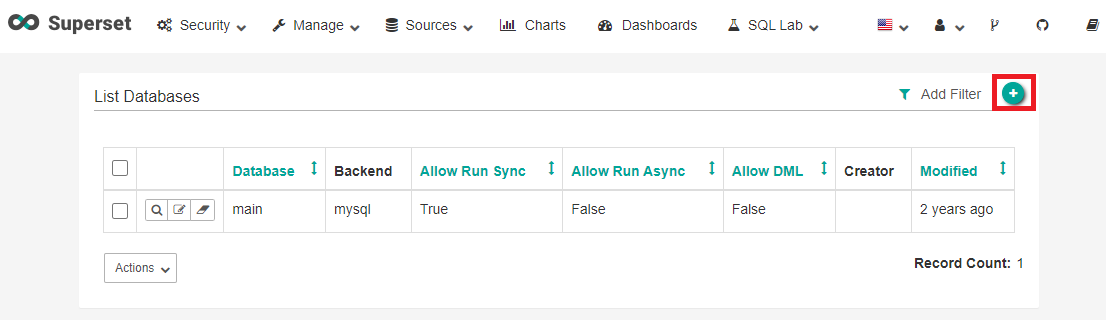
다음과 같이 입력한다.
- Database - 테스트 목적이므로 test라고 입력했다. 원하는 이름을 사용한다.
- SQLAlchemy URI - mysql+pymysql://superset@localhost:3306/superset (잘 모르겠다면 main Database의 설정을 참고하자)
- Expose this DB in SQL Lab - 체크 (SQL Lab에서 쿼리할 수 있다.)

나머지 옵션은 그대로 두고 하단의 Save 버튼을 클릭한다.
테스트를 위한 Table 생성 (데이터 업로드)
테스트를 진행하기 위해 CSV 파일을 업로드하여 Table을 생성한다.
구글링으로 데이터 분석이나 데이터 과학을 위한 예제 데이터를 가져와서 사용하는 것을 권장한다. (CSV 포맷)
단, 검색에 유용하도록 모든 컬럼의 이름이 존재해야 한다.
예를 들어 stock_px.csv 파일은 파이썬 라이브러리를 활용한 데이터 분석 (한빛미디어)에서 다룬 예제 데이터 중 하나이다.
상단의 Sources를 선택하고 Upload a CSV를 클릭한다.

다음과 같이 입력한다.
- Table Name - 테스트 목적이므로 test라고 입력했다. 원하는 이름을 사용한다.
- CSV File - 사용하려는 CSV 파일을 선택한다.
- Con - 위에서 생성한 test Database를 클릭한다. (기본 값은 main이므로 변경해야 한다.)
- Delimiter - 테스트에 사용한 CSV 파일의 구분자도 ,라서 변경하지 않았다. 공백인 경우는 \s+, 탭인 경우는 \t+를 입력한다.

테스트이므로 나머지 옵션은 그대로 두고 하단의 Save 버튼을 클릭한다.
만약 CSV 파일을 업로드하다 오류가 발생한 경우 Table Exists 옵션을 Append에서 Replace로 변경하고 다시 진행한다.
Table을 삭제하고 재생성하기 때문에 정상적으로 진행된다.
테스트를 하면서 다양한 옵션을 적용해 보는 것을 권장한다.
test라는 이름의 Table이 생성 된 것을 확인할 수 있다.

SQL Query 테스트
업로드한 테이블의 데이터를 조회해본다.
상단의 SQL Lab을 클릭하고 SQL Editor를 클릭한다.
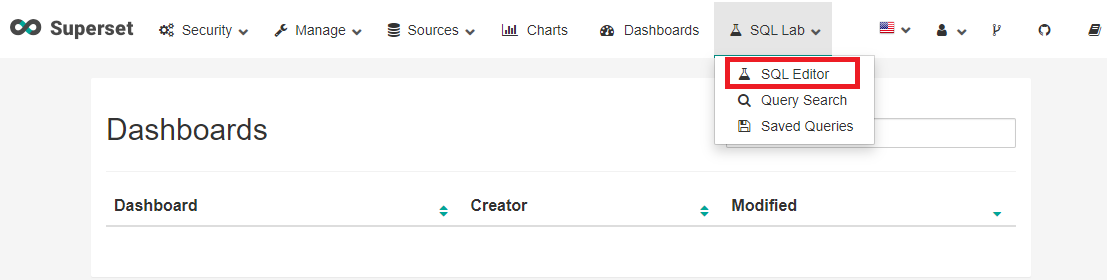
좌측의 Database를 클릭하고 test를 선택한다.

쿼리는 다음과 같이 작성한다.
LIMIT 100은 100개만 출력한다는 뜻이다. 스키마와 데이터 구성을 볼 때에는 많이 출력할 필요는 없다.
# 아래 쿼리의 test는 Table 이름이다.
SELECT *
FROM test
LIMIT 100;
Run Query 버튼을 클릭하면 하단에 쿼리 결과가 출력된다.

결과 상단의 Visualize 버튼을 클릭하면 시각화 할 컬럼과 Chart 타입을 설정할 수 있다.

Visualize 버튼을 클릭하면 시각화 페이지로 이동한다.
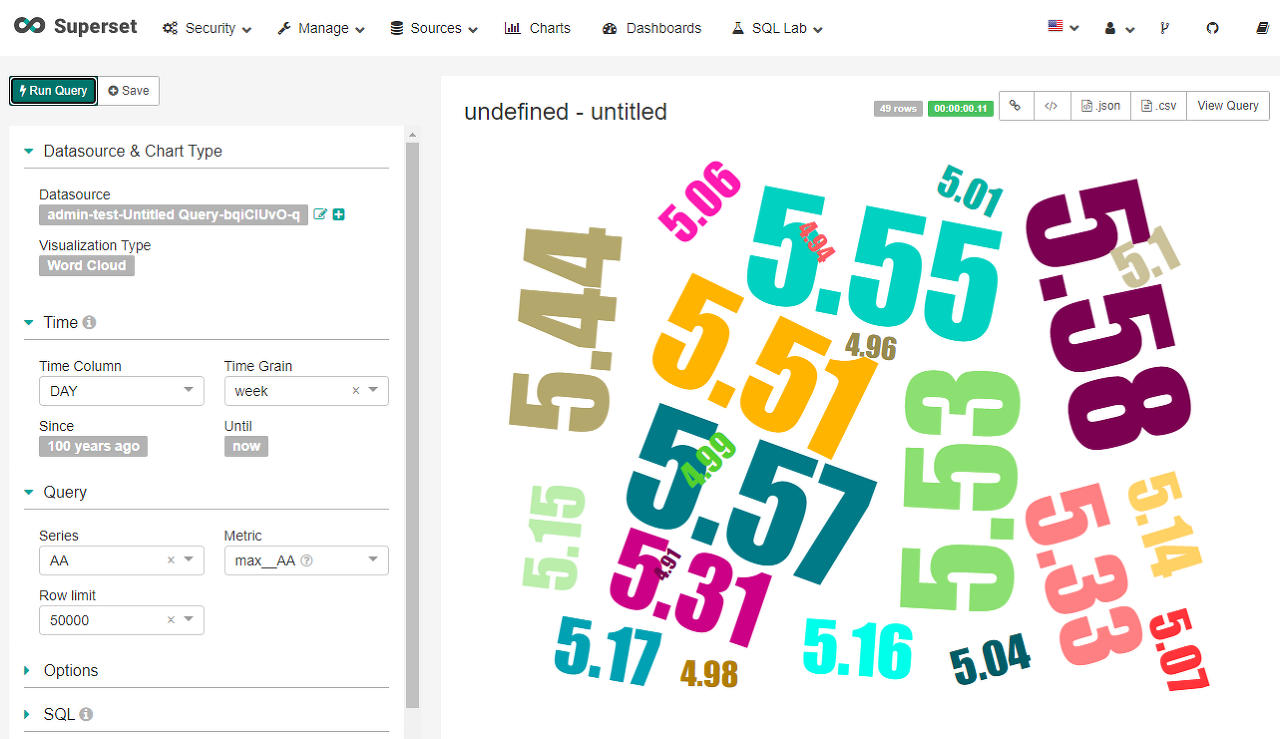
아래는 다음 옵션으로 생성한 시각화 결과이다.
- Visualization Type - Word Count
- Time Grain - week
- Series - AA
- Metric - max__AA
생성한 Table, Database 삭제
Table 삭제
시각화를 진행하다 보면 시각화 데이터를 별도의 Table로 저장하기 때문에 불필요한 Table이 생성된다.
Sources의 Tables로 이동한다.

데이터를 업로드한 test Table과 시각화에 사용한 Untitled Query Table이 존재한다.
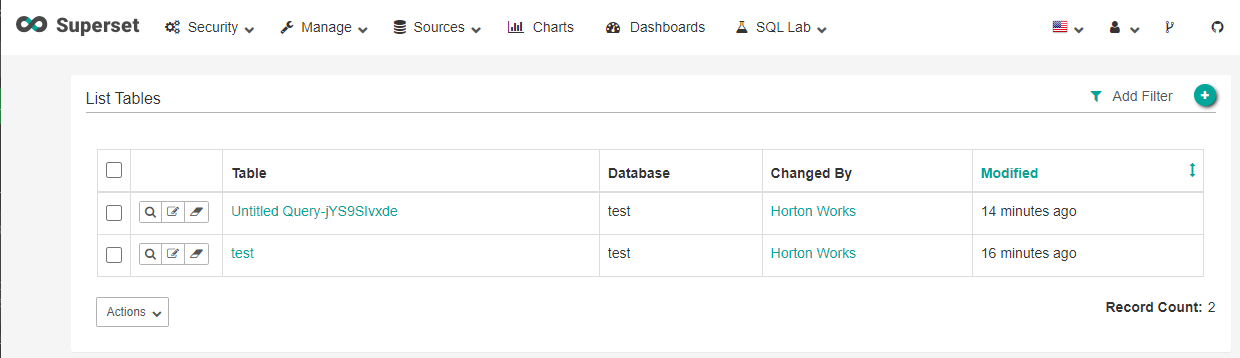
삭제하려는 Table에 체크하고 하단의 Actions를 누르고 Delete를 클릭한다.
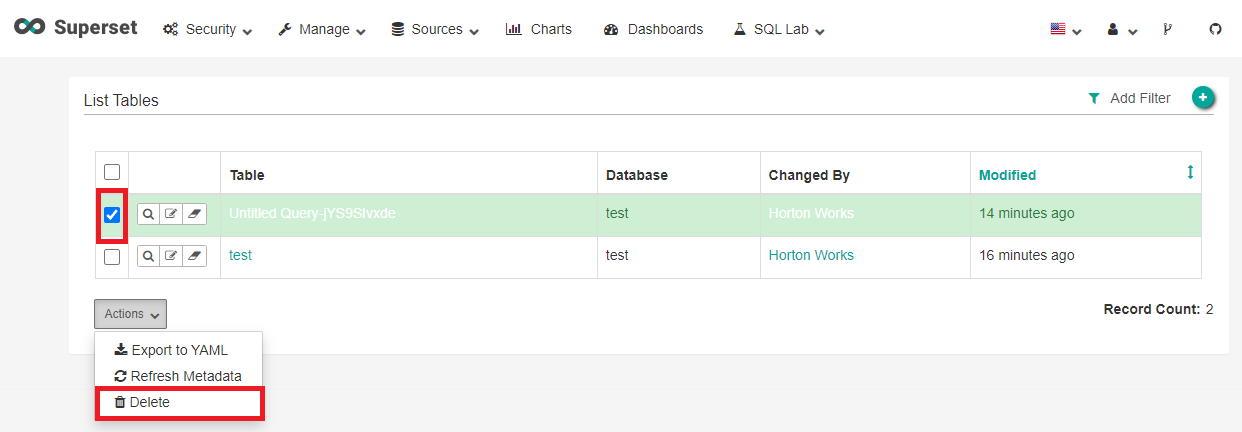
OK 버튼을 클릭한다.

선택한 테이블이 삭제되었다.

Database 삭제
상단의 Sources를 누르고 Databases를 클릭한다.

이후 과정은 Table 삭제와 동일한 방법으로 진행한다.
'::: 데이터 분석 :::' 카테고리의 다른 글
| Zeppelin에서 데이터 탐색하기 (2) | 2021.10.25 |
|---|---|
| Zeppelin 설정하고 노트북 생성하기 (0) | 2021.10.21 |
| HDP Sandbox 3.0.1 사용 관련 참고 사항 (0) | 2021.10.14 |
| HDP Sandbox 3.0.1의 HDFS에 admin, root 계정 권한 추가하기 (0) | 2021.10.11 |
| HDP Sandbox 3.0.1 Docker 이미지로 Ambari 로그인하기 (0) | 2021.10.07 |