HDFS에 데이터를 업로드하고 Zeppelin으로 분석과 탐색을 진행하기 위해서는 추가 설정을 진행해야 한다.
Ambari 설정과 Hadoop, Spark 등 서비스 설치는 아래 포스팅 (문서)를 참고한다.
HDFS와 Zeppelin 추가 설정은 다음 순서로 진행한다.
-
Ambari Admin에서 계정 추가
-
하둡 설정 변경 (Ambari, CentOS, HDFS)
-
Zeppelin 설정 변경 (Ambari, Interpreter)
-
데이터 업로드 및 탐색
Ambari Admin에서 계정 추가
현재 Ambari에 접근 가능한 계정은 admin 밖에 없다.
따라서 Ambari UI를 사용하기 위한 계정을 생성해야 한다.
Ambari Dashboard 화면에서 우측 상단의 amin - Manage Ambari 버튼을 클릭한다.

Ambari 관리 화면으로 전환되며, 좌측의 Users 를 클릭하고 ADD USERS를 선택한다.

아래와 같은 계정 정보 등록 화면이 출력된다.
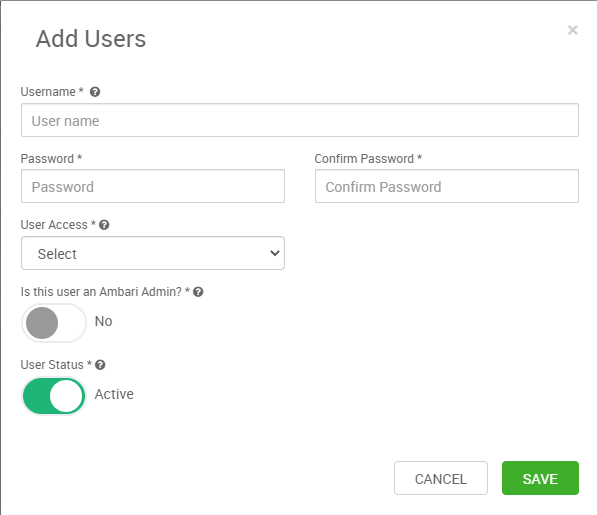
다음과 같이 계정을 생성한다.
|
구분
|
관리자
|
사용자
|
|
ID
|
bdpadmin (클러스터명+admin)
|
bdpuser (클러스터명+user)
|
|
User Access
|
Cluster Adminitstrator
|
Cluster (or Service) Operator
|
|
Is this user an Ambari Admin?
|
Yes
|
No
|
|
User Status
|
Active
|
Active
|
추가가 완료되면 아래와 같이 계정이 생성된다.
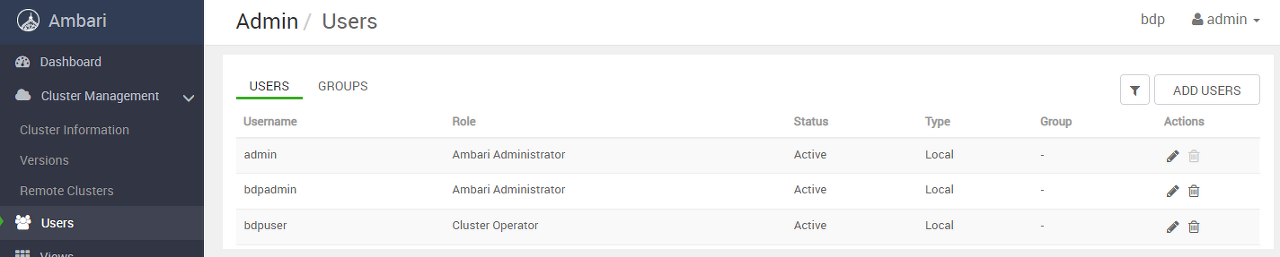
필요에 따라 Admin 계정의 User Status를 Inactive로 변경한다.
하둡 설정 변경
HDFS에서 데이터 파일을 읽고 쓰기 위한 설정을 진행한다.
Ambari UI에서 설정 변경
Ambari의 HDFS 설정 화면에서 값을 변경한다.
HDFS의 CONFIGS 화면에 진입한다.

중간의 Advanced hdfs-site를 선택한다.

스크롤을 내리다보면 dfs.permissions.enabled 항목이 존재한다.
HDFS 파일 작업에 권한 제어 적용 여부 옵션이다. true로 되어 있는 경우 false로 변경한다.
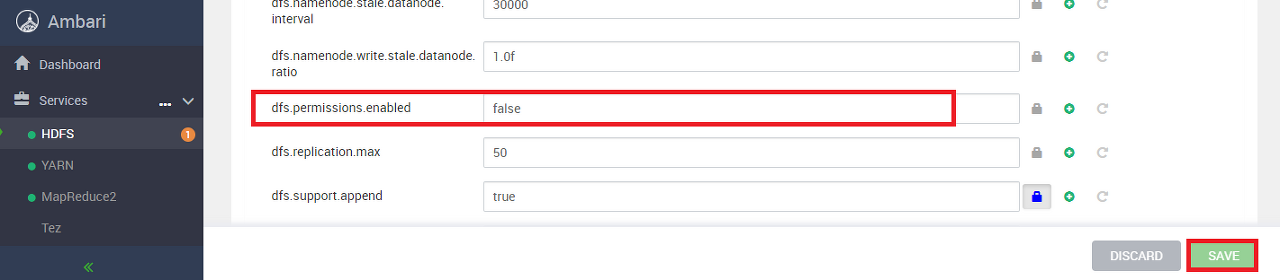
하둡 파일 시스템 권한 관리 관련 (dfs.permissions.enabled)
하둡 파일 시스템의 권한 기능을 끄는 옵션이므로, 실수로 잘못 삭제하는 등의 위험성이 존재한다.
나중에는 해당 옵션을 끄지 않고 사용할 수 있는 방법을 찾아 볼 필요가 있다.
(하지만 구글링 해보면 테스트 환경이라 그런지 대부분 false로 변경하는 것을 가이드 한다.)
설정을 바꾸고 저장하면 영향을 받는 노드와 구성 요소 목록이 표시된다.
그리고 재시작 여부를 묻는데, Restart All Affected를 클릭해서 전체 재시작을 적용한다.
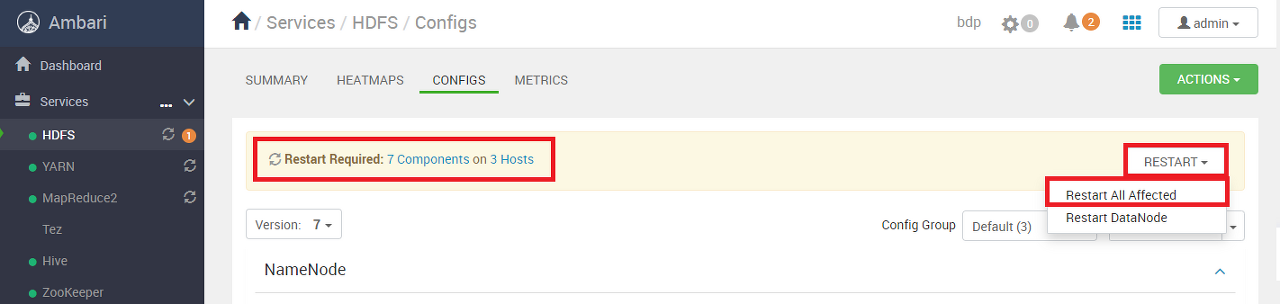
HDFS 서비스의 재시작에 대한 확인 메시지로 CONFIRM RESTART ALL 버튼을 클릭한다.

아래 화면과 같이 서비스 재시작이 진행된다.

CentOS 설정 변경
각 노드들에 ssh로 접근해서 설정을 변경한다.
계정 생성
먼저 CentOS7에서 계정을 생성한다.
Master Node에서 진행한 사항은 다음과 같다.
관리를 위한 bdpadmin 계정과 일반 사용을 위한 bdpuser 계정으로 구분했다.
$ ssh ambari@192.168.56.51
$ sudo useradd bdpadmin # 계정 생성
$ sudo passwd bdpadmin # 비밀번호 변경
$ sudo useradd bdpuser # 계정 생성
$ sudo passwd bdpuser # 비밀번호 변경
# 나머지 노드에서도 진행Ambari를 설치하면서 Client를 설치한 나머지 노드에서도 진행한다.
너무 많은 경우에는 NameNode와 SNameNode가 설치 된 PC에서만 해도 되지 않을까 싶다.
hadoop, hdfs 그룹에 추가
계정 생성 이후에는 /etc/group의 hadoop, hdfs 그룹에 추가한다.
계정에 대해 하둡의 HDFS 영역에 쓰기 권한을 부여한다.
Master Node에서 진행한 사항은 다음과 같다.
관리를 위한 bdpadmin 계정과 일반 사용을 위한 bdpuser 계정으로 구분했다.
$ ssh ambari@192.168.56.51
$ sudo usermod -aG hdfs bdpadmin
$ sudo usermod -aG hadoop bdpadmin
$ sudo usermod -aG hdfs bdpuser
$ sudo usermod -aG hadoop bdpuser
# 나머지 노드에서도 진행위의 계정 생성을 진행한 노드에서는 모두 진행한다.
HDFS에 디렉토리 생성
HDFS에 해당 계정이 데이터를 읽고 쓰기 위한 디렉토리를 생성한다.
Hadoop Client가 설치 된 노드 한 군데에서만 진행하면 된다.
사용자 계정 경로 생성
아래와 같이 사용자 계정 경로를 생성하고 권한을 777로 변경한다.
$ su bdpadmin
$ hadoop fs -mkdir /user/bdpadmin
$ hadoop fs -chmod 777 /user/bdpadmin
$ su bdpuser
$ hadoop fs -mkdir /user/bdpuser
$ hadoop fs -chmod 777 /user/bdpuserData 경로 생성
데이터를 공용으로 사용하기 위한 data 경로를 생성한다.
주로 정기적으로 생성하는 데이터에 대한 경로를 의미한다.
$ su bdpadmin
$ hadoop fs -mkdir /data
$ hadoop fs -chmod 777 /data
Workspace 경로 생성
임시로 데이터를 업로드하고 분석하기 위한 workspace 경로를 생성한다.
해당 경로는 일시적인 데이터 작업을 위한 경로를 의미한다.
$ su bdpadmin
$ hadoop fs -mkdir /data/workspace
$ hadoop fs -chmod 777 /data/workspace
tmp 경로 권한 변경
HDFS의 tmp 경로 권한을 777로 변경해야 다른 서비스들의 동작이 원활하다.
$ sudo su hdfs
$ hadoop fs -chmod 777 /tmpZeppelin 설정 변경
실제 데이터를 읽고 탐색하기 위한 Zeppelin의 설정을 변경한다.
Ambari UI에서 설정 변경
Ambari의 Zeppelin 설정 화면에서 값을 변경한다.
Zeppelin Nodebood의 CONFIGS 화면에 진입한다.
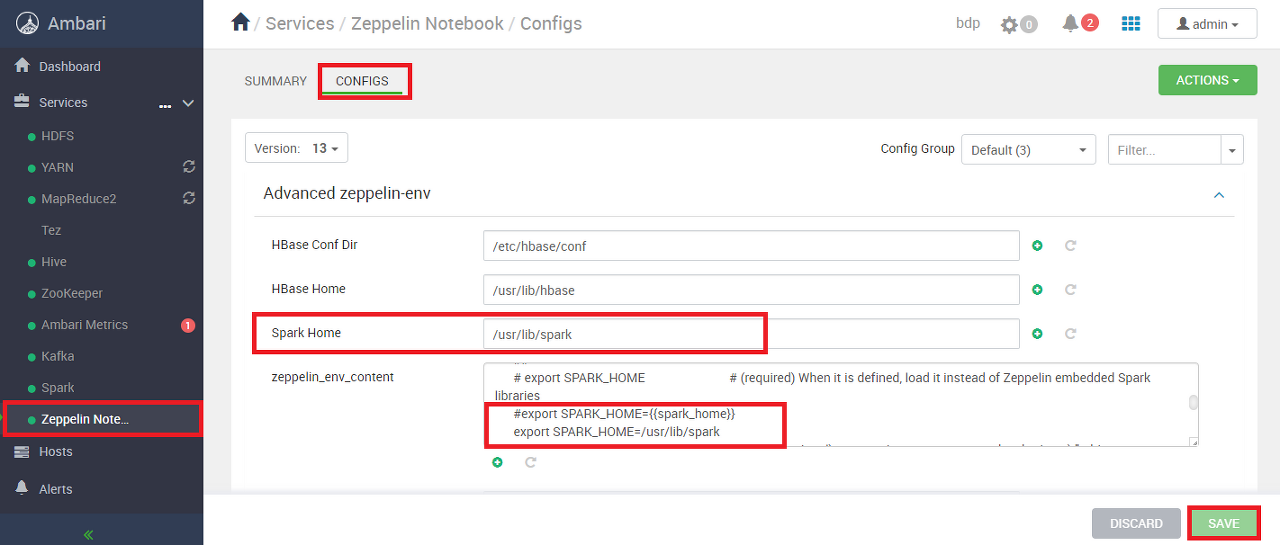
SPARK_HOME 경로 변경
Spark Home과 zeppelin_ennv_content의 export SPARK_HOME 값을 변경한다.
기본 값은 /usr/lib/current/spark-client 으로 되어 있는데 실제 경로는 /usr/lib/spark이다.
사용자 계정 추가
Zeppelin은 Java에서 제공하는 Shiro라는 도구를 통해 접근 제어를 제공한다. (심지어 Apache에서 관리한다.)
계정의 비밀번호는 maven의 shiro-tools-hasher를 이용한 SHA-256 값을 사용하여 설정한다.
아래와 같이 진행한다.
$ wget https://repo1.maven.org/maven2/org/apache/shiro/tools/shiro-tools-hasher/1.3.2/shiro-tools-hasher-1.3.2-cli.jar
$ scp -P 22 ./shiro-tools-hasher-1.3.2-cli.jar ambari@192.168.56.51:/home/ambari
$ ssh ambari@192.168.56.51
$ java -jar shiro-tools-hasher-1.3.2-cli.jar -p
Password to hash: # 암호 입력
Password to hash (confirm): # 암호 재입력
$shiro1$SHA-256$500000$JE.......생략........AA==$NS0dkPA........생략.......8G06N/DGBJVqc6Nt84m0aTw=
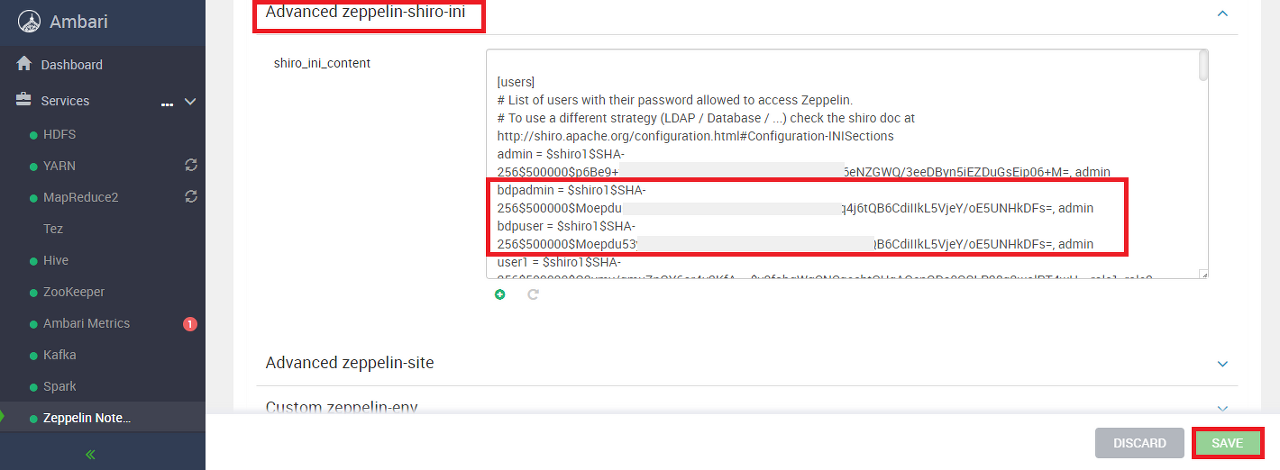
$Zeppelin의 CONFIGS에서 Advanced zeppelin-shiro-ini 메뉴를 찾는다.
shiro_ini_content의 [users] 항목에 아래와 같이 추가한다.
# 계정명 $shiro1-SHA256해시 권한 형태
bdpadmin $shiro1$SHA-256$500000$JE.......생략........8G06N/DGBJVqc6Nt84m0aTw= admin
bdpuser $shiro1$SHA-256$500000$JE.......생략........8G06N/DGBJVqc6Nt84m0aTw= admin관리자 계정과 사용자 계정을 의미하는 bdpadmin, bdpuser를 추가했다.
제일 앞이 계정명, 가운데가 shiro Hash, 마지막이 권한이다. 실제로 입력하면 아래와 같다.
Shiro 설정 관련 내용은 아래 사이트를 참고하였다.
익명 접근을 허용하고자 하는 경우
Zeppelin에서 로그인 없이 사용하려는 경우에는 아래와 같이 진행한다.
익명 접근 관련 확인 필요
아래 방법이 권고 사항이라 진행해봤으나 노트북 목록이 표시되지 않았다.
특정 설정이 누락되었는지 확인이 필요하다.
테스트 환경과 향후 사용 환경에서는 bdpadmin, bdpuser 같은 계정을 사용할 예정이다.
따라서 익명 접근 허용 설정은 참고로 남겨둔다.
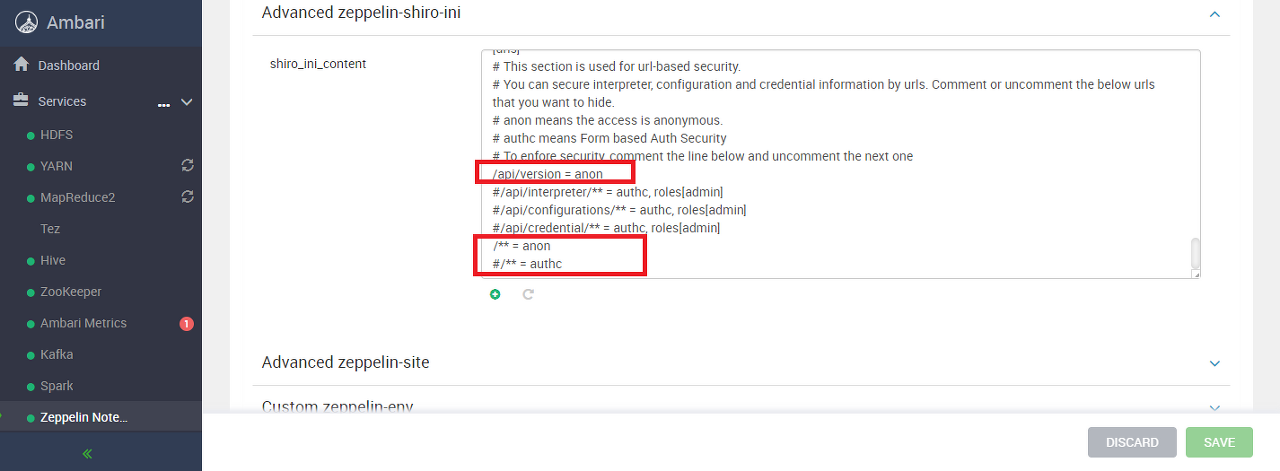
Zepplin의 CONFIGS 화면에서 Advanced zeppelin-site를 선택한다.
zeppelin.anonymous.allowed 값을 false에서 true로 변경한다.

Zepplin의 CONFIGS 화면에서 Advanced zeppelin-shiro-ini를 선택한다.
shiro_ini_content 의 값을 다음과 같이 변경한다. anon 에 주석을 해제하고 authc 에 주석을 적용한다.
Zeppelin Interpreter 설정 변경
마지막으로 Zeppelin의 Interpreter에서의 설정을 변경한다.
-
Zeppelin 구동을 위한 시스템 환경 설정 - Ambari의 Zeppelin 메뉴에 있는 CONFIG 항목
-
Zeppelin 서비스의 데이터 분석 환경 설정 - Zeppelin 웹UI(9995포트)의 Interpreter 항목
Zeppelin 로그인 창이 나타나면 Zeppelin에 등록한 bdpadmin 계정으로 로그인한다.

정상적으로 로그인되면 우측 상단에 bdpadmin 계정이 표시된다.
계정명을 클릭하고 Interpreter를 선택한다.

Interpreter 화면의 스크롤을 아래로 쭉 내리면 Spark 항목이 존재한다.
알파벳 순으로 배치되어 가장 마지막에 위치한다.
각 항목 별로 아래와 같이 변경한다.
|
구분
|
설정값
|
기본값
|
|
SPARK_HOME
|
/usr/lib/spark
|
/usr/lib/current/spark-client
|
|
spark.master
|
yarn
|
local[*]
|
|
spark.submit.deployMode
|
client
|
_blank
|
|
spark.app.name
|
zeppelin
|
_blank
|
설정을 변경한 화면은 다음과 같다.

스크롤을 아래로 더 내리면 Spark 실행을 위한 리소스 설정 항목이 나온다.
필요에 따라 자유롭게 조정한다.
일반적으로는 기본 값을 활용하다 메모리 부족 오류가 발생하거나 성능이 너무 안나올때 조정하는 편이다.
각 항목 별로 아래와 같이 설정한다.
|
구분
|
설정값
|
기본값
|
설명
|
|
spark.driver.cores
|
1 (기본값 유지)
|
1
|
Spark Driver의 프로세스 코어수 (cluster모드만 해당)
|
|
spark.driver.memory
|
1g (기본값 유지)
|
1g
|
Spark Driver의 메모리 크기
|
|
spark.executor.cores
|
2 (향후 3으로 증가)
|
1
|
Spark Executor의 1개당 프로세스 코어수 |
|
spark.executor.memory
|
2g (향후 3~4g로 증가)
|
1g
|
Spark Executor의 1개당 메모리 크기
|
|
spark.executor.instances
|
2 (기본값 유지, 향후 3~4로 증가)
|
2
|
Spark Executor의 전체 개수
|
설정을 변경한 화면은 다음과 같다.

화면 하단의 Save 버튼을 누르면 Lazy Execution에 대한 메시지가 출력된다.
변경 된 설정은 향후 Zeppelin Notebook에서 해당 Interpreter가 실행될때 적용 된다는 의미이다.
이로서 모든 설정 변경을 마쳤다.
실제 데이터 업로드
설정이 제대로 적용되었는지 확인하기 위해 샘플 데이터를 이용하여 테스트를 진행한다.
사용하는 데이터는 2019년 기준 넷플릭스 영화와 TV Show 목록이며, 출처는 다음과 같다.
Netflix Movies and TV Shows
Listings of movies and tv shows on Netflix - Regularly Updated
www.kaggle.com
해당 파일을 다운로드하고 scp를 이용하여 Master Node에 업로드한다.
그리고 SSH로 Master Node에 접속하여 HDFS의 data 경로에 해당 파일을 업로드한다.
$ scp -P 22 netflix_titles_nov_2019.csv bdpadmin@192.168.56.51:/home/bdpadmin # Master Node 업로드
$ ssh bdpadmin@192.168.56.51
# 192.168.56.51 가상환경 내부
$ hadoop fs -put netflix_titles_nov_2019.csv /data # HDFS에 업로드
$ hadoop fs -chmod 777 /data/netflix_titles_nov_2019.csv # 파일 권한 변경 (모든 권한 허용)
$ hadoop fs -ls /data # 업로드 데이터 존재 여부 확인
업로드에 성공하면 다음과 같이 HDFS에 파일이 존재하는 것을 확인할 수 있다.

참고로 읽기만 하는 원본 데이터 파일인 경우 보호를 위해 w 권한은 제거해도 될 것으로 판단된다.
Zeppelin으로 데이터 탐색
해당 데이터가 Zeppelin에서 잘 읽히는지 테스트를 진행한다.
웹 브라우저에서 Zeppelin WebUI (9995 포트)로 접속하고 bdpadmin으로 로그인한다.
상단의 Notebook → Create new note를 클릭하고 신규 노트북을 생성한다.
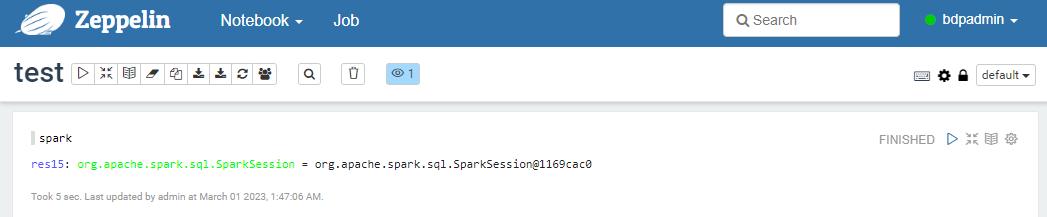
첫 번째 블록에 spark이라 입력하고 우측의 화살표를 클릭하거나 Shift + Enter를 입력한다.
정상적으로 실행되면 아래와 같이 SparkSession 인스턴스 정보가 출력된다. (시간이 약간 걸린다.)
아래와 같이 Spark으로 CSV 파일을 읽고 스키마와 레코드 상위 20개를 출력한다.
val csvDf = spark.read.option("header", "true").csv("/data") # CSV 파일 읽기 (첫행은 컬럼명으로 사용)
csvDf.printSchema # 데이터의 스키마 출력
csvDf.show(false) # 레코드의 상위 20개 출력출력되는 화면은 다음과 같다. 정상적으로 동작하는 것을 확인할 수 있다.

해당 데이터에 대해 더 살펴보고자 하는 경우 아래 포스팅을 참고하여 데이터 탐색을 진행한다.
Spark WebUI (8088 포트 / 또는 Zeppelin 코드 상단의 SPARK JOB)에서 확인해보면 아래와 같이 Spark Job이 실행 된 것을 확인할 수 있다.
Job Group 항목에 zeppelin에서 admin 권한으로 실행한 작업임을 알 수 있다.

Hadoop YARN의 WebUI (8088)를 확인해보면 Zeppelin 계정에 의해 Spark이 실행 중인 것을 확인할 수 있다.
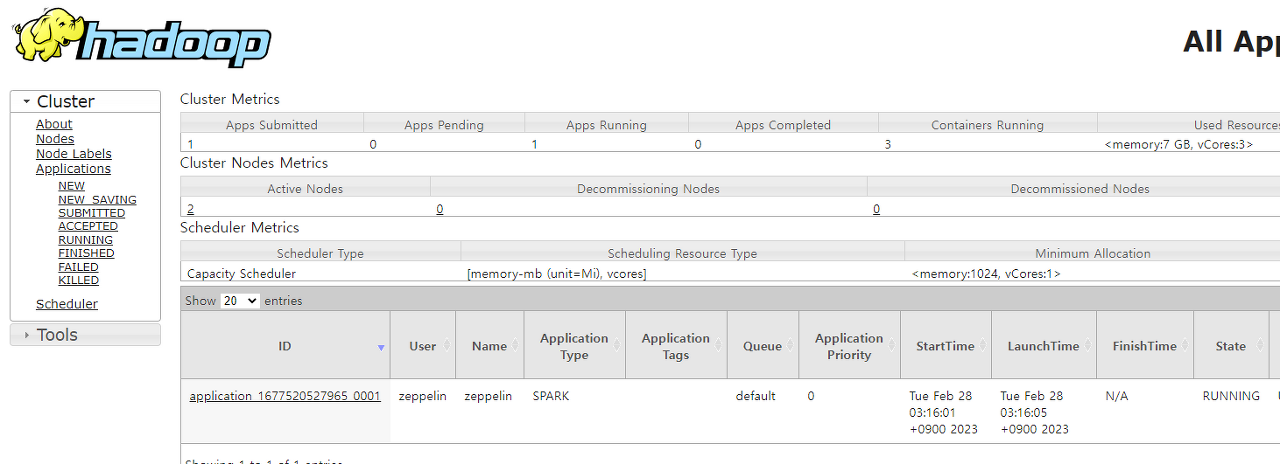
여기까지 진행하면 아래 단계가 모두 해결 된 것이다.
-
Ambari를 통해 Hadoop과 Spark을 설치
-
HDFS에 데이터를 업로드하고 권한 설정
-
Zeppelin에서 Spark을 이용한 데이터 탐색
'::: 데이터 분석 :::' 카테고리의 다른 글
| [Ambari 11] Ambari 설치하면서 변경하는 설정 정리 (95) | 2023.04.27 |
|---|---|
| [Ambari 10] Apache Bigtop 빌드 안하고 쉽게 설치하기 (0) | 2023.04.06 |
| [Ambari 8] 설치 완료 이후 서비스 탐색 (0) | 2023.03.27 |
| [Ambari 7] Ambari 설정과 Hadoop, Spark 설치 (1) | 2023.03.23 |
| [Ambari 6] CentOS 가상 이미지 복제와 Ambari 설치 (0) | 2023.03.20 |