Ambari 설치를 마쳤으므로 Ambari에 접속해서 하둡과 관련 서비스들을 설치한다.
아래 과정으로 진행한다.
-
Ambari 웹페이지 포트포워딩
-
Ambari 접속과 Agent 구성
-
하둡과 관련 서비스 설치와 시작
-
스냅샷 생성
CentOS 가상 이미지 복제와 Ambari 설치 방법은 아래 포스팅 (문서)를 참고한다.
PostgreSQL 설정과 id_rsa 파일 복사를 진행하지 않았다면 위의 포스팅을 참고하여 먼저 수행한다.
Ambari 웹페이지 접속
Ambari 웹페이지 포트포워딩
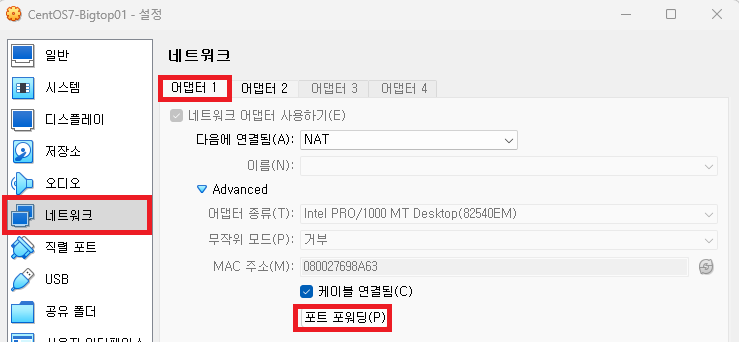
VirtualBox에서 Master 가상 환경의 포트포워딩을 설정한다.
Master 가상환경을 선택하고 설정 버튼을 클릭한다.

네트워크 - 어댑터 1을 선택한다.
Advanced를 클릭해서 메뉴를 확장하고 포트포워딩을 클릭한다.
(NAT 네트워크만 포트포워딩이 가능하다.)
우측의 + 버튼을 두번 클릭하고 각각 아래와 같이 입력한다.
-
Ambari - 8080 포트
-
PostgreSQL - 5432 포트
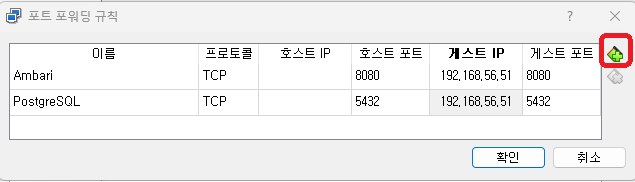
이름은 식별하기 쉽도록 직관적으로 입력한다.
게스트 IP는 연결할 가상머신의 IP 주소 (호스트전용어댑터)를 입력한다.
하둡 관련 서비스의 웹 UI 포트 추가
하둡 관련 서비스 설치가 완료되면 각 서비스의 웹 UI 포트를 추가한다.
해당 설정이 적용되지 않으면 접속이 불가능하다.
Ambari 접속과 Agent 구성
Ambari 접속
호스트 (물리) PC에서 8080 포트로 접속한다.
(ex. http://192.168.56.51:8080 or http://localhost:8080)

기본 id와 password는 admin이다. 로그인에 성공하면 클러스터 구성 메뉴로 이동한다.
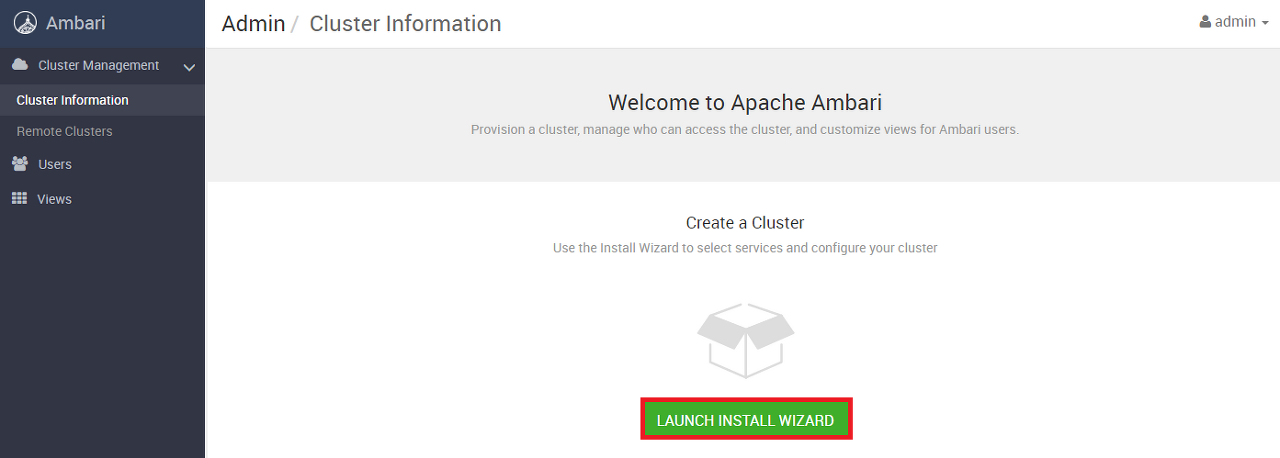
화면 중앙의 LAUNCH INSTALL WIZARD를 클릭한다.
클러스터 이름 부여
생성하고자 하는 클러스터 이름을 부여한다. Bearpooh Data Platform의 약자로 bdp를 입력했다.

BGTP 스택 확인 및 설정
이전에 bigtop-ambari-mpack이 정상적으로 설치 된 경우 BGTP-1.0 스택 정보가 출력된다.
목록이 정상적으로 출력되는지 확인한다.

스크롤을 아래로 내리면 저장소 (Repository) 설정하는 부분이 있다.
-
Use Public Repository 선택
-
Base URL은 그대로 유지
-
Skip Repository Base URL validation (Advanced) 항목 체크
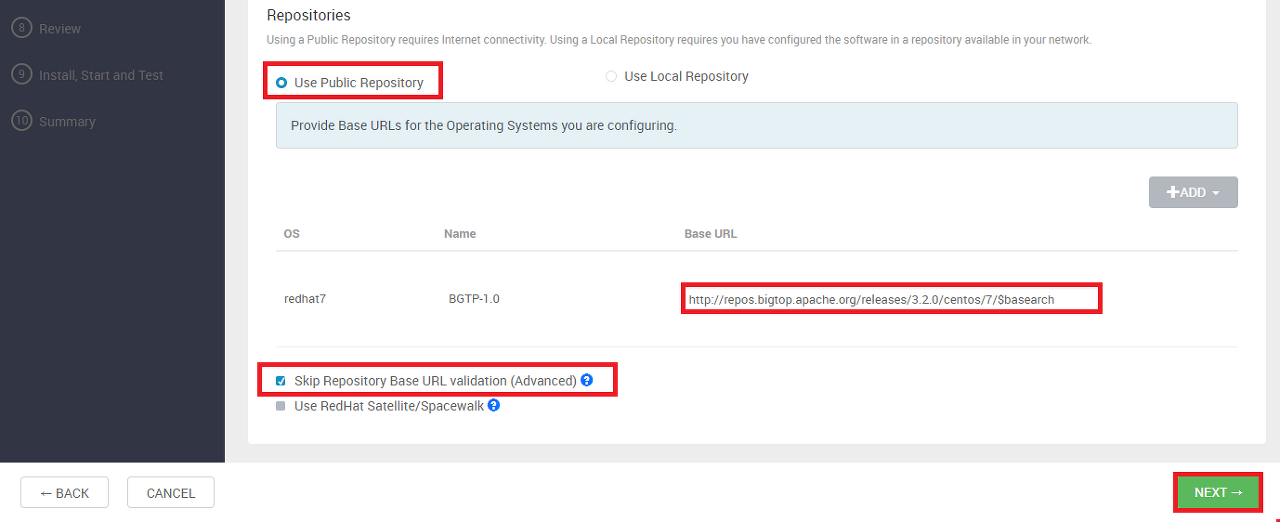
Skip Repository Base URL validation (Advanced) 항목 체크 필요
해당 옵션을 해제하면 Bigtop 저장소에 정상적으로 연결되는지 확인하는데 오류가 발생한다.
저장소 검증 과정을 생략해도 정상적으로 진행되므로 해당 옵션에 체크해야 한다.
Ambari Agent 구성
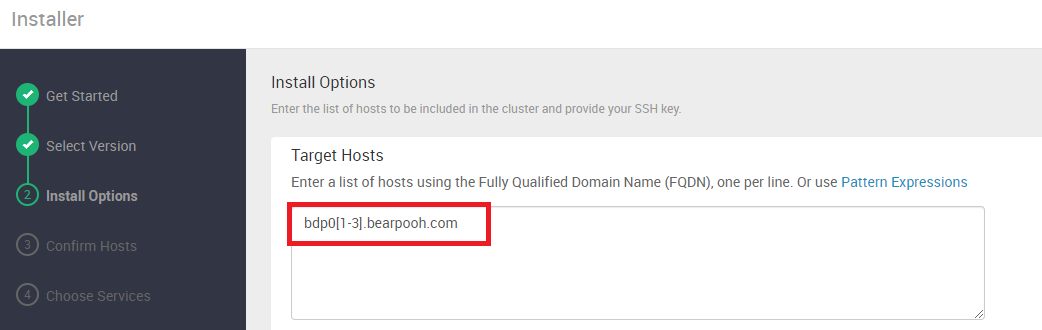
Target Hosts에는 연결할 가상머신들의 FQDN 주소를 입력한다.
앞서 가상머신의 hosts 파일에 설정한 주소들을 입력한다.
-
bdp01.bearpooh.com
-
bdp02.bearpooh.com
-
bdp03.bearpooh.com
노드가 20~30개 되는 경우 일일이 입력할 수 없으므로, 축약한 패턴으로 입력할 수 있다
아래와 같이 bdp0[1-3].bearpooh.com으로 입력하면 위의 3줄을 한줄로 입력할 수 있다.
CHOOSE FILE을 클릭하고 id_rsa 파일을 선택한다.
버튼 우측에 파일명이 출력되고 아래에 id_rsa 파일 내용이 자동으로 입력된다.
SSH User Account에는 root 대신 ambari를 입력한다.
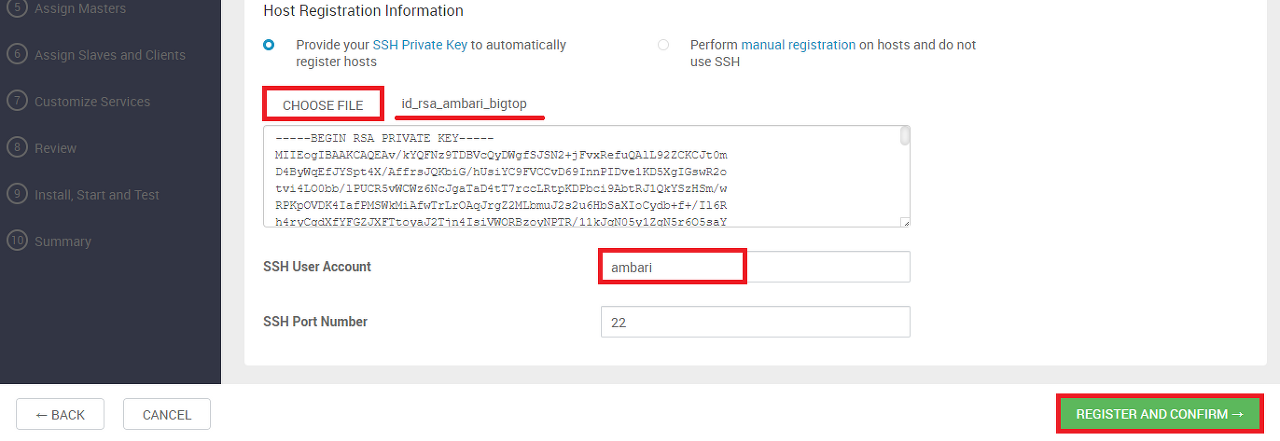
입력을 마치고 REGISTER AND CONFIRM 버튼을 클릭하면 Agent 설치 및 등록 화면으로 이동한다.
아래와 같이 입력한 노드 목록이 출력되고 Installing 메시지가 출력된다.

설치가 완료되면 Registering으로 표시되고 최종 성공하면 Succes 메시지가 출력된다.
Next를 클릭하여 다음 단계를 진행한다.

(이 화면을 만나기가 생각보다 어렵다.)
Preparing에서 Installing으로 넘어가지 않는 경우
설치를 진행하다보면 Preparing에서 Installing으로 넘어가지 않고 무한 대기하는 경우가 있다.
기존에 설치에 실패한 이력이 초기화 되지 않아 발생하는 것으로 다음 명령을 통해 ambari-server를 초기화한다.
$ ambari-server stop $ ambari-server reset $ ambari-server start
그래도 Preparing에서 진행되지 않는다면 다음과 같이 setup 명령을 다시 실행한다.
설정 값은 바꾸지 않고 엔터만 입력한다.
$ ambari-server stop $ ambari-server setup # 기존 설정은 유지하고 엔터엔터 $ ambari-server start
https://community.cloudera.com/t5/Support-Questions/Ambari-Status-quot-Preparing-quot-in-confirmation-of-hosts/td-p/184096
하둡과 관련 서비스 설치와 시작
설치할 서비스 선택
Ambari를 통해 설치할 하둡과 관련 서비스들을 선택한다.
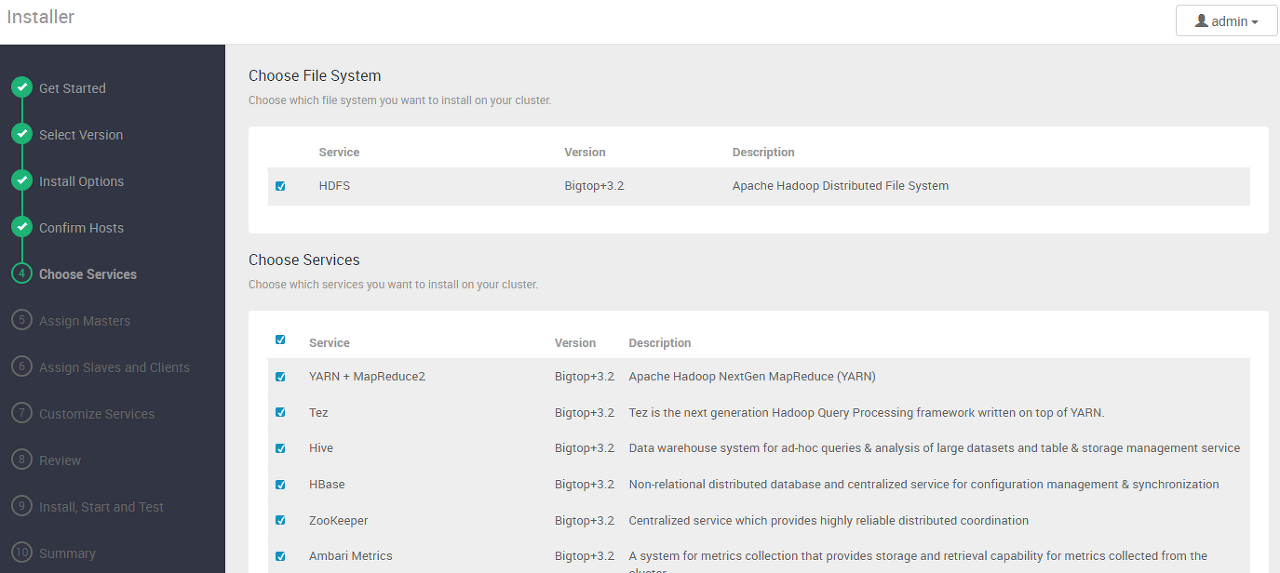
향후 활용 계획과 테스트임을 고려하여 아래 항목은 제외했다.
-
HBase
-
Flink
-
Solr
Master Node 분배
선택한 서비스들의 Master Node들을 지정한다.
이 부분부터는 하둡 에코시스템에 대한 지식을 요구하므로 정확하지 않을 수 있다.
(앞으로 많은 공부가 필요하다.)
몇 가지 원칙은 다음과 같다.
-
NameNode, ResourceManager는 Node01 (Ambari Server와 동일)
-
MetricCollector는 Node01에 설치
-
Zookeeper Server는 모든 노드 설치
-
Hive, Spark은 같은 노드에 배치
-
Node02는 Secondary Name Node이므로 SName Master 지정
-
Node03은 데이터 노드 역할을 수행하므로 Master 지정 제외
-
Grafana, Zeppelin, Spark History Server 등은 Name02에 설치
-
나머지는 적절히 분배
테스트 환경에서는 다음과 같이 구성했다.

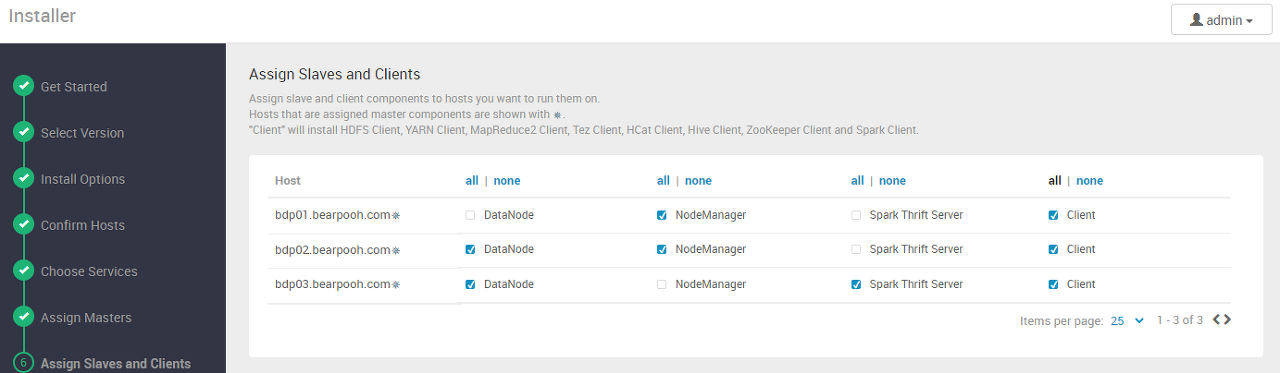
Worker Node 분배
선택한 서비스들의 Worker Node들을 지정한다.
이 부분부터는 하둡 에코시스템에 대한 지식을 요구하므로 정확하지 않을 수 있다. (앞으로 공부가 필요하다.)
몇 가지 원칙은 다음과 같다.
-
Name Node에는 Data Node 할당 자제 (노드가 적으면 어쩔 수 없지만 최소화)
-
노드가 4개 이상이면 Master와 Worker 노드 분리 필수
Client는 모든 서비스들의 클라이언트 구성을 의미하는데, 일단 모든 노드에 설치하는 것으로 선택했다.
(역시 이 부분도 추가 공부가 필요하다.)
테스트 환경에서는 다음과 같이 구성했다.
하둡 관련 서비스 상세 설정
서비스 비밀번호 설정
Grafana와 Hive의 비밀번호를 설정한다.
사용할 비밀번호를 입력한다.

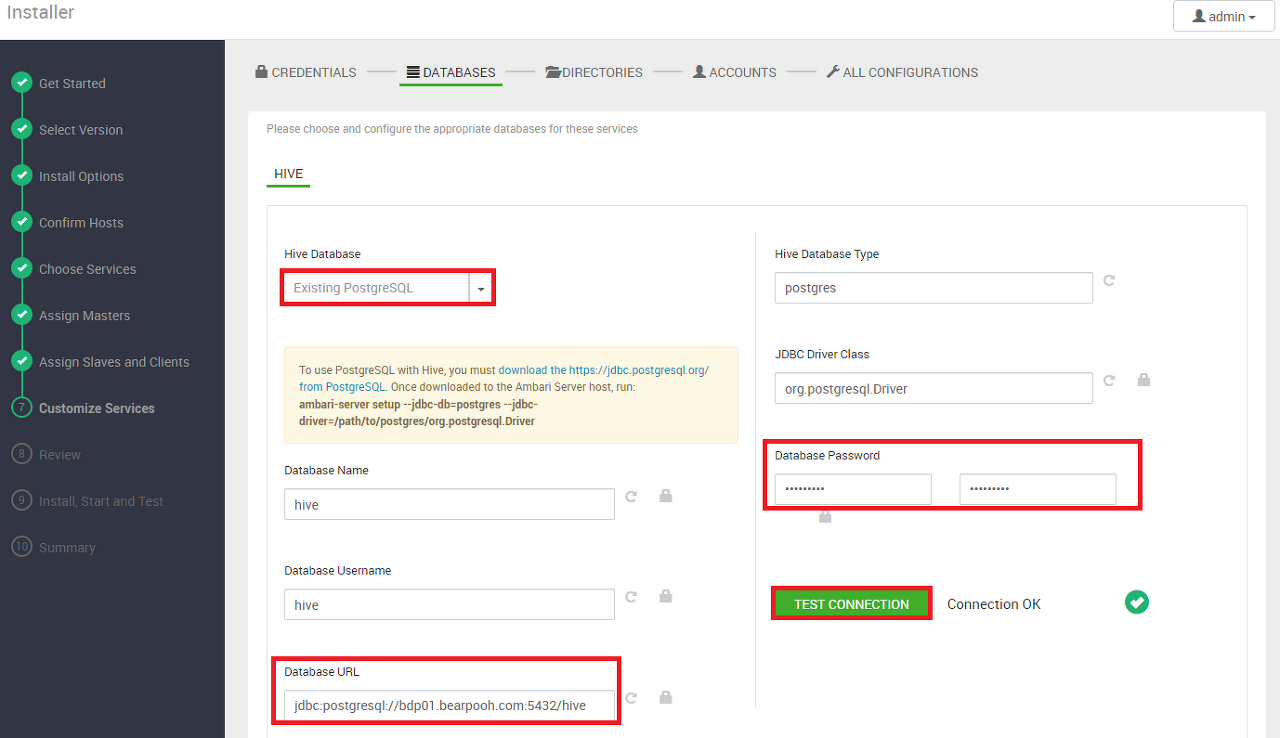
Hive Database 설정
Hive 정보를 저장하는 데이터베이스를 설정한다.
일단 테스트 환경이므로 Ambari 메타 정보를 저장하는 Master Node의 PostgreSQL 활용한다.
-
Hive Database - Existing PostgreSQL을 선택한다.
-
Database URL - PostgreSQL이 설치 된 Master Node의 주소를 지정한다. (bdp02로 되어 있으면 bdp01로 변경)
-
Database Password - PostgreSQL에 생성한 hive 계정의 비밀번호를 입력한다.
-
TEST CONNECTION - 연결이 성공하면 Connection OK 메시지가 출력된다.
서비스의 디렉토리 설정
HDFS 설정만 변경하고 나머지 서비스는 기본값을 유지한다.
가상머신을 생성할때 /data 파티션에 가장 많은 용량을 할당했다.
HDFS의 DATA DIRS의 DataNode, NameNode, Secondary NameNode 경로 앞에 /data를 추가한다.

HDFS 최종 설정
ACCOUNT는 설정 항목이 없으므로 Next를 클릭한다.
ALL CONFIGURATIONS에서는 HDFS 설정만 추가 진행한다.
HDFS 탭의 하단으로 내려보면 hadoop.proxyuser 항목이 있다. *를 입력하고 넘어간다.

아래 화면이 출력되는 경우 Hive Database 연결에 대한 확인이 완료되지 않았다는 의미이다.
이전 단계에서 이미 확인했다면 PROCEED ANYWAY를 클릭한다.

또는 ALL CONFIGRUATIONS - HIVE - DATABASE 탭을 선택하고, TEST CONNECTION 버튼을 눌러 OK를 확인한다.
설정 값 최종 검토 및 배포
위의 설정 값들은 나중에 변경 가능하다.
Review에서 설정 값을 최종 확인하고 DEPLOY 버튼을 클릭하여 배포를 시작한다.

서비스 설치 진행
아래 화면과 같이 각 Node에 설치가 진행된다.

설치 과정은 상당히 오래 걸리므로 인내심을 가지고 기다린다.
보통 35% 정도까지는 설치, 그 이후는 서비스 시작 과정이다.
서비스 시작 과정이 약 10~15분 정도 소요된다.
설치 과정 중 오류가 발생하면 원인 확인 및 트러블슈팅을 진행한다.
설치 완료
설치가 완료되면 Ambari 모니터링 페이지로 자동 이동한다.
설치 및 서비스 시작 중 오류가 발생한 경우 아래와 같이 Warning 메시지가 표시된다.

Next 버튼이 활성화 되면 클릭한다. 아래와 같이 Ambari Dashboard를 확인할 수 있다.

이전에 진행했던 HDP Sandbox와 UI가 동일한 것을 확인할 수 있다.
HDP Sandbox 2.6.5 Docker 설정과 Ambari 로그인하기
참고사항 본 글은 2018년에 기술 조사를 진행하면서 확인한 내용으로, 최신 상황에 맞게 업데이트 하였으나 일부 부족한 내용이 있을 수 있습니다. 빅데이터나 하둡 관련 전문가가 아니기 때문에
www.bearpooh.com
HDP Sandbox 3.0.1 Docker 이미지로 Ambari 로그인하기
## 참고사항 ## 빅데이터나 하둡 관련 전문가가 아니기 때문에 일부 부족한 내용이 있을 수 있습니다. 셋팅과 기본적인 사용 외에, 하둡과 관련 생태계 운영의 트러블 슈팅은 잘 모릅니다. 오픈소
www.bearpooh.com
정상 시작되지 않은 서비스는 우측 상단의 Service Restart 버튼을 클릭하면 재시작 할 수 있다.
좌측에 Spark, Hive가 빨간색으로 표시되는데 해당 서비스를 재시작해본다.
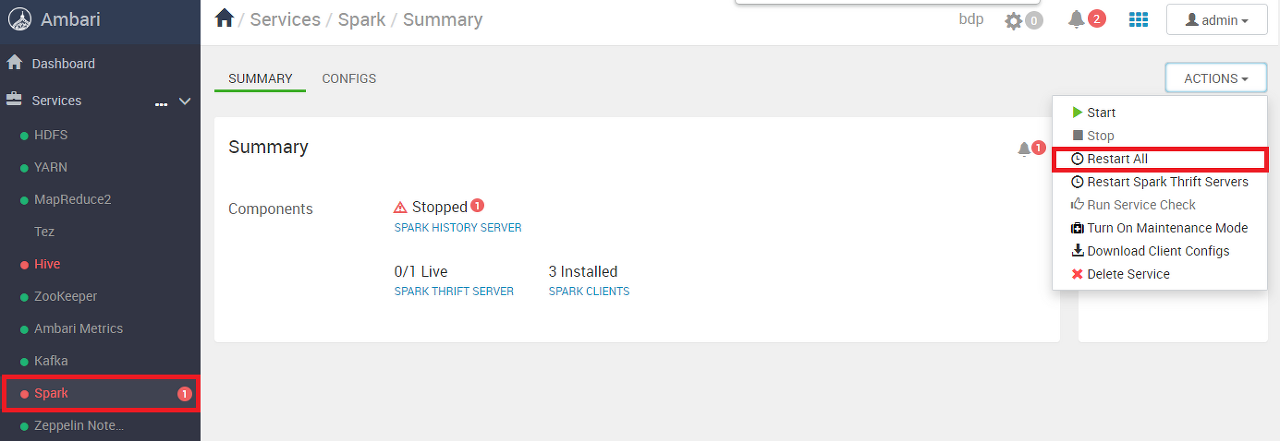
재시작 버튼을 누르면 아래와 같이 상태를 확인할 수 있다.
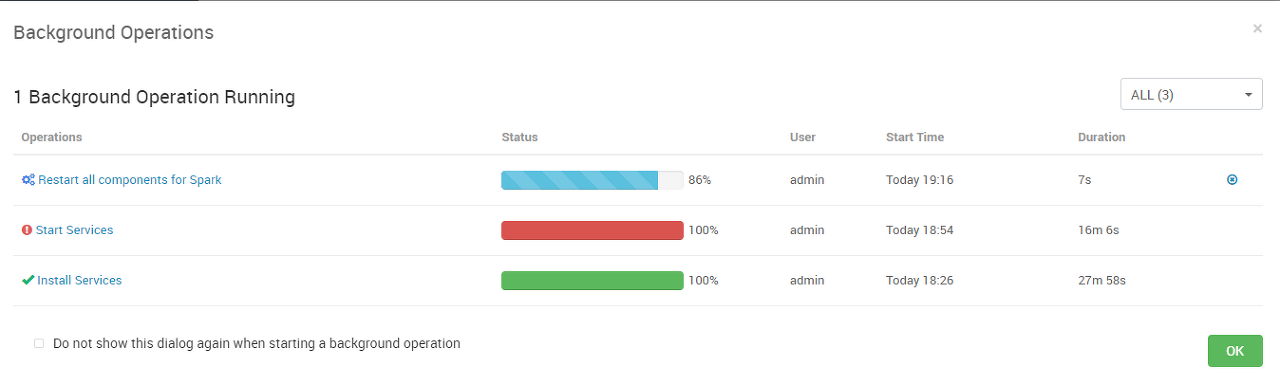
재시작이 성공적으로 완료되면 왼쪽 메뉴가 모두 파란색으로 변경된다.
스냅샷 생성
Master Node와 Worker Node 모두 스냅샷 - 찍기 버튼을 클릭해서 스냅샷을 생성한다.
-
스냅샷 이름 - Step 6
-
스냅샷 설명 (Master / Worker) - 하둡 및 관련 서비스 설치 완료
Ambari, 하둡, 관련 서비스의 모든 설치는 완료되었다.
각 서비스들을 확인하는 과정은 다음 포스팅(문서)로 진행한다.
'::: 데이터 분석 :::' 카테고리의 다른 글
| [Ambari 9] 데이터 탐색을 위한 하둡과 제플린 설정 (0) | 2023.03.30 |
|---|---|
| [Ambari 8] 설치 완료 이후 서비스 탐색 (0) | 2023.03.27 |
| [Ambari 6] CentOS 가상 이미지 복제와 Ambari 설치 (0) | 2023.03.20 |
| [Ambari 5] Bigtop 설치와 Ambari 빌드 (2) | 2023.03.16 |
| [Ambari 4] CentOS 7 추가 설정 (3) | 2023.03.13 |