MongoDB의 데이터 모델링 패턴에 대해 정리한다.
MongoDB의 Document 구조와 관계 패턴은 아래 포스팅을 참고한다.
MongoDB의 구조와 특징은 아래 포스팅을 참고한다.
본 포스팅은 MongoDB 공식 문서와 아래 문서를 참고하여 작성했다.
정말 깔끔하게 정리가 잘 되어 있으므로 해당 포스팅을 읽어볼 것을 권한다.
MongoDB의 공식 문서는 아래 사이트를 참고한다.
Model Tree Structure Pattern
Document 구조의 레퍼런스 방식에서 Document 간의 연결에 대해 다뤘다.
이러한 Document들의 연결 관계가 계층적인 Tree 구조인 경우 5가지 패턴을 사용할 수 있다.
MongoDB 공식 문서에서 제공하는 아래 그림을 기준으로 진행한다.

레퍼런스 방식에서 언급했듯이 각 Document들은 별도의 Collection으로 구분하는 것이 권장 된다.
Parent References
자식 Document에 부모 Document에 대한 참조를 지정한다.
가장 아래 Document 부터 Bottom-up 방식으로 작성한다.
예제 코드는 다음과 같다.
db.categories.insertMany( [
{ _id: "MongoDB", parent: "Databases" },
{ _id: "dbm", parent: "Databases" },
{ _id: "Databases", parent: "Programming" },
{ _id: "Languages", parent: "Programming" },
{ _id: "Programming", parent: "Books" },
{ _id: "Books", parent: null }
] )부모 Document를 바로 찾는 경우에 유용하다.
parent 필드를 사용하면 직접 연결 된 자식 Document 탐색도 가능하다.
그러나 모든 자식 Document를 찾는 경우에는 부적합하다.
자세한 내용은 아래 문서를 참고한다.
Child References
부모 Document에 자식 Document에 대한 참조를 지정한다.
가장 아래 Document 부터 Bottom-up 방식으로 작성한다.
예제 코드는 다음과 같다.
db.categories.insertMany( [
{ _id: "MongoDB", children: [] },
{ _id: "dbm", children: [] },
{ _id: "Databases", children: [ "MongoDB", "dbm" ] },
{ _id: "Languages", children: [] },
{ _id: "Programming", children: [ "Databases", "Languages" ] },
{ _id: "Books", children: [ "Programming" ] }
] )자식 Document를 바로 찾는 경우에 유용하다.
children 필드를 사용하여 부모 Document를 찾을 수 있다.
그러나 children 필드의 배열 탐색도 진행해야 하므로 Parent Reference 보다 느리다.
모든 부모 Document를 찾는 것은 매우 부적절하다.
자세한 내용은 아래 문서를 참고한다.
Array of Ancestors
자식 Document에 부모와 조상인 Document에 대한 참조를 지정한다.
가장 아래 Document부터 Bottom-up 방식으로 작성한다.
부모 Document는 조상 Document에도 포함된다.
예제 코드는 다음과 같다.
db.categories.insertMany( [
{ _id: "MongoDB", ancestors: [ "Books", "Programming", "Databases" ], parent: "Databases" },
{ _id: "dbm", ancestors: [ "Books", "Programming", "Databases" ], parent: "Databases" },
{ _id: "Databases", ancestors: [ "Books", "Programming" ], parent: "Programming" },
{ _id: "Languages", ancestors: [ "Books", "Programming" ], parent: "Programming" },
{ _id: "Programming", ancestors: [ "Books" ], parent: "Books" },
{ _id: "Books", ancestors: [ ], parent: null }
] )상위 Document나 자식 Document를 모두 찾아야 하는 경우 적합하다.
ancestors 필드를 사용하면 부모 Document 상위의 Document 탐색이 가능하다.
그러나 ancestors 필드의 배열 탐색을 진행해야 하므로 조상 Document가 많을 수록 탐색 속도가 느려질 수 있다.
또한 부모 Document가 여러 개인 경우에는 부적합하다.
자세한 내용은 아래 문서를 참고한다.
Materialized Paths
Document에 상위 Document에 대한 참조를 경로 형태로 지정한다.
가장 상위 Document 부터 Top-down 방식으로 작성한다.
배열 형태가 아닌 콤마(,)로 구분한 문자열 형태로 지정하며, 정규식을 이용하여 하위 Document를 탐색한다.
예제 코드는 다음과 같다.
db.categories.insertMany( [
{ _id: "Books", path: null },
{ _id: "Programming", path: ",Books," },
{ _id: "Databases", path: ",Books,Programming," },
{ _id: "Languages", path: ",Books,Programming," },
{ _id: "MongoDB", path: ",Books,Programming,Databases," },
{ _id: "dbm", path: ",Books,Programming,Databases," }
] )하위 Document를 찾아야 하는 경우 적합하다.
path 필드가 배열이 아닌 문자열 형태이므로 하위 트리 탐색이 Array of Ancestors 보다 빠르다.
배열이 아닌 문자열이므로 공통 부모 Document를 찾는 경우에는 탐색 속도가 더 느려질 수 있다.
자세한 내용은 아래 문서를 참고한다.
Nested Sets
조금 특이한 구조를 가지고 있으며 데이터구조론에서 다루는 트리 탐색과 비슷하다.
트리의 각 Document에 번호를 부여하고, 해당 Document의 부모와 자식 노드를 번호로 지정한다.
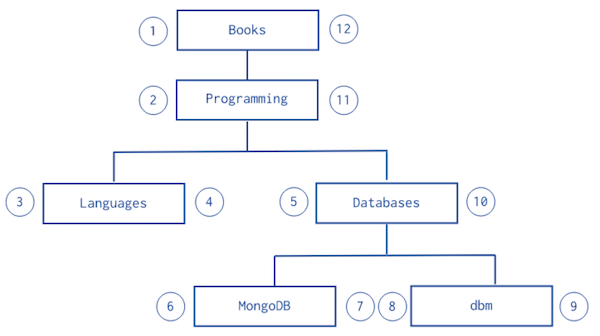
예제 코드는 다음과 같다.
db.categories.insertMany( [
{ _id: "Books", parent: 0, left: 1, right: 12 },
{ _id: "Programming", parent: "Books", left: 2, right: 11 },
{ _id: "Languages", parent: "Programming", left: 3, right: 4 },
{ _id: "Databases", parent: "Programming", left: 5, right: 10 },
{ _id: "MongoDB", parent: "Databases", left: 6, right: 7 },
{ _id: "dbm", parent: "Databases", left: 8, right: 9 }
] )배열이나 문자열이 아닌 정수로 연결 관계를 표현하므로 자식 Document를 찾는데 가장 빠르고 효율적이다.
그러나 계층 구조가 변경되면 각 Document에 대한 번호를 새로 부여해야 하므로 연산 비용이 비싸다.
따라서 추가, 삭제, 수정과 같은 데이터의 변경이 없는 정적인 구조에 적합하다.
자세한 내용은 아래 문서를 참고한다.
Data Modeling Pattern
앞서 MongoDB는 Join 연산을 제공하지 않기 때문에 데이터 설계가 중요하다고 언급했다.
관건은 참조하는 Collection을 최소화하고 데이터를 단순하게 설계하는 것이다.
MongoDB를 선택하는 가장 큰 이유 중 하나가 빠른 속도 때문인데, 데이터 설계가 잘못되면 그 장점을 활용하기 어렵다.
이러한 이유로 MongoDB에서도 데이터의 디자인 패턴에 대한 가이드를 제공한다.
아래 그림은 mongodb 사이트에서 제공하는 디자인 패턴들의 활용 분야에 대해 정리한 것이다.
데이터의 출처나 활용 방안에 따른 데이터의 디자인 패턴을 선택할 때 참고하면 좋은 것 같다.
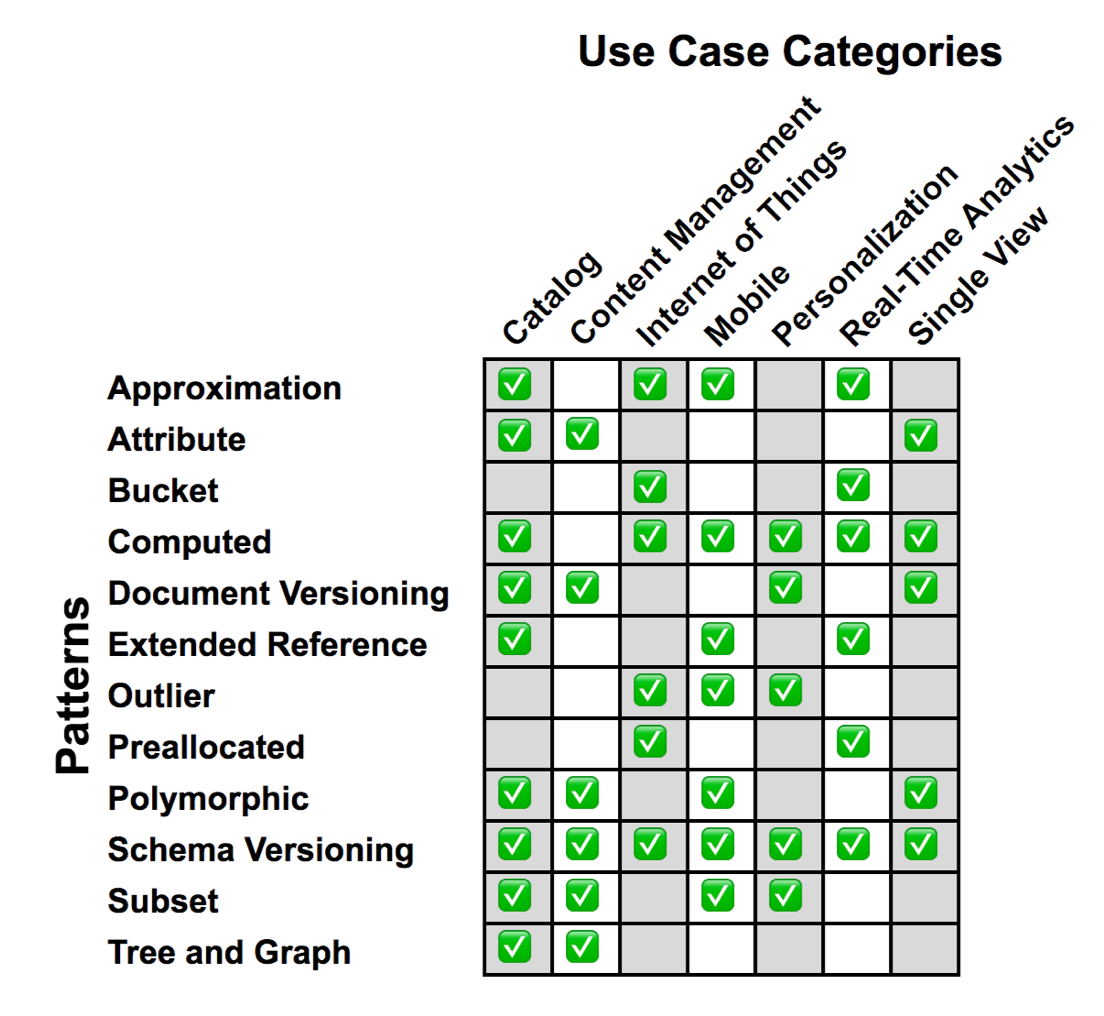
해당 내용은 아래 사이트를 참고한다.
Schema Versioning
MongoDB와 같은 NoSQL은 RDBMS와 달리 데이터의 구조를 의미하는 스키마에 대한 엄격함이 덜하다.
서비스 운영에서 발생하는 스키마의 변경에 유연하게 대처할 수 있지만, 데이터 관리 입장에서는 마이그레이션에 대한 부담이 존재한다.
서비스나 응용 프로그램이 개선 되면서 데이터의 항목(필드)가 추가, 변경, 삭제 되는 변경이 발생한다.
Schema Versioning은 각 Document에 대한 버전 정보를 기록하는 방법을 제공한다.
아래와 같은 데이터가 있다고 해보자.
{
"_id": "<ObjectId>",
"name": "Darth Vader",
"home": "503-555-0100",
"work": "503-555-0110",
"mobile": "503-555-0120"
}새로운 스키마로 변경된 경우 아래와 같이 schema_version을 지정하면 된다.
{
"_id": "<ObjectId>",
"schema_version": "2",
"name": "Anakin Skywalker (Retired)",
"contact_method": [
{ "work": "503-555-0210" },
{ "mobile": "503-555-0220" },
{ "twitter": "@anakinskywalker" },
{ "skype": "AlwaysWithYou" }
]
}
Schema 버전이 여러 개가 생기는 경우 아래와 같이 처리하면 된다.
-
서비스나 응용 프로그램에서 Schema의 모든 버전을 모두 읽고 처리하도록 설계한다.
-
또는 기존 데이터를 새로운 Schema 버전에 맞게 마이그레이션을 진행한다.
전자는 마이그레이션에 대한 부담은 적지만, 관리적인 부분에서 스키마가 다른 데이터가 섞이는 부담이 발생한다.
후자는 마이그레이션에 대한 부담이 생기지만, 관리적인 부분에서 일관적인 스키마를 유지할 수 있다.
운영 상황과 필요에 따라 선택할 수 있으므로 적절한 방법을 선택한다.
schema_version에 대한 자세한 내용은 아래 사이트를 참고한다.
Attribute
동일한 필드를 묶어서 인덱싱 수를 줄이는 패턴이다.
아래와 같이 '국가별 개봉 날짜' 같은 필드는 반복되는 패턴이다.
{
title: "Star Wars",
director: "George Lucas",
...
release_US: ISODate("1977-05-20T01:00:00+01:00"),
release_France: ISODate("1977-10-19T01:00:00+01:00"),
release_Italy: ISODate("1977-10-20T01:00:00+01:00"),
release_UK: ISODate("1977-12-27T01:00:00+01:00"),
...
}국가별 개봉 날짜는 '국가'와 '날짜' 필드로 분리해서 '개봉' 필드로 묶을 수 있다.
{
title: "Star Wars",
director: "George Lucas",
…
releases: [
{
location: "USA",
date: ISODate("1977-05-20T01:00:00+01:00")
},
{
location: "France",
date: ISODate("1977-10-19T01:00:00+01:00")
},
{
location: "Italy",
date: ISODate("1977-10-20T01:00:00+01:00")
},
{
location: "UK",
date: ISODate("1977-12-27T01:00:00+01:00")
},
…
],
…
}조회 대상 필드가 release.location과 release.date로 단순화 되었다.
자세한 사항은 아래 문서를 참고한다.
Extended Reference
서로 관계가 있는 Document에서 자주 사용되는 데이터를 임베디드 방식으로 저장해두는 패턴이다.
MongoDB에서는 Join 연산을 지원하지 않기 때문에 사용하는 방법이다.
자주 사용하는 다른 Document의 일부 항목을 임베디드 형태로 저장해서, 미리 Join 해 놓은 것처럼 사용하는 방식이다.
Join을 대체할 수 있는 장점이지만 중복 데이터가 발생하는 것은 단점이다.
Document의 구조에서 다룬 레퍼런스 방식은 기본적으로 최소 두 번의 쿼리가 필요하다.
-
최초 쿼리 : 필요한 데이터를 읽어온다. 특정 필드의 값이 다른 Document의 식별자이다.
-
이후 쿼리 : 해당 식별자에 해당하는 데이터를 확인하기 위해 읽어온다.
이러한 패턴의 쿼리가 빈번하고, 연결 된 Document에서 특정 필드만 사용하는 경우 유용하다.
아래 그림처럼 주문 정보에 고객의 배송지 정보가 항상 필요하다면 Extented Reference 패턴을 고려해볼 수 있다.

주문 이벤트가 발생하면 해당 고객의 정보를 쿼리해서 배송지 정보를 가져온다.
해당 이벤트의 주문 관련 정보와 결합하여 임베디드 방식으로 MongoDB에 저장한다.
조회하면 Join 없이 한 번의 쿼리로 고객의 배송지 정보를 확인할 수 있다.
자세한 사항은 아래 문서를 참고한다.
Subset
서로 관계가 있는 Document에서 자주 사용되는 데이터를 임베디드 방식으로 저장해두는 패턴이다.
Extented Reference는 단일 Document의 일부 영역을 미리 저장해두는 방식이다.
Subset은 여러 Document 중에 자주 사용하는 일부 목록을 저장하는 방식이다.
그림으로 표현하면 다음과 같다.

온라인 쇼핑몰에서 최근 리뷰 5개만 표시되고, 더보기를 클릭해야 전체 리뷰 목록을 볼 수 있는 것과 동일하다.
인기 상품 목록을 우선 표시하고 더보기를 클릭해야 전체 상품 목록이 표시 되는 것도 동일하다.
미리 결과를 만들어 놓고 요청이 있을 경우만 추가 쿼리를 진행하므로, MongoDB의 조회 요청을 줄일 수 있다.
한쪽 Document의 데이터가 수정 되면 해당 데이터를 참조하는 Document의 데이터도 함께 수정해야 한다.
자세한 사항은 아래 문서를 참고한다.
Computed
MongoDB는 분산 환경이기 때문에 Aggregation 연산은 비싼 연산이다.
비싸다는 의미는 네트워크 통신을 필요로 하고 연산량이 많은 것을 의미한다. 모두 비용이기 때문이다.
메모리 기반 데이터 분산 처리 시스템인 Spark도 같은 이유로 Aggregation은 비싼 연산으로 분류된다.
MongoDB는 여러 Shard에 데이터가 나눠서 저장되어 있는 분산 시스템 방식을 사용하고 있다.
여러 곳에 있는 데이터를 한 곳에 모아서 가공하는 연산을 해야 하므로 네트워크와 연산 자원의 소모가 많아진다.
Computed 패턴은 이러한 Aggregation을 대체할 수 있도록 미리 통계 수치를 계산해서 삽입해 놓는다.
연산 결과에 약간의 오차를 허용하는 경우 사용하면 유용하다.

우리가 반올림 하는 이유를 생각해보면 이해하기 쉽다.
자세한 내용은 아래 문서를 참고한다.
Bucket
특정 필드를 기준으로 Document를 묶는 패턴이다.
실시간 로그와 같은 동일한 스키마를 가지는 시계열 데이터에 적합하다.
아래와 같은 시계열이 있다고 가정해보자.
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:00:00.000Z"),
temperature: 40
}
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:01:00.000Z"),
temperature: 40
}
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:02:00.000Z"),
temperature: 41
}아래와 같이 묶어서 표현 가능하다.
{
sensor_id: 12345,
start_date: ISODate("2019-01-31T10:00:00.000Z"),
end_date: ISODate("2019-01-31T10:59:59.000Z"),
measurements: [
{
timestamp: ISODate("2019-01-31T10:00:00.000Z"),
temperature: 40
},
{
timestamp: ISODate("2019-01-31T10:01:00.000Z"),
temperature: 40
},
...
{
timestamp: ISODate("2019-01-31T10:42:00.000Z"),
temperature: 42
}
],
transaction_count: 42,
sum_temperature: 2413
}Attribute는 단일 Document 내부의 필드를 묶는 것이다.
Bucket은 여러 Document의 동일 필드들을 단일 Document에 포함하는 것이다.
Document의 크기가 16MB로 제한되기 때문에, 해당 제한을 초과하지 않도록 주의해야 한다.
위의 데이터에서도 start_date와 end_date가 지정 된 것을 참고한다.
해당 Bucket에 포함 된 데이터에 대한 Aggregation 연산은 단일 Document 내부에서 진행 가능하다.
Aggregation 연산을 낮은 비용에 할 수 있다.
자세한 사항은 아래 문서를 참고한다.
'::: IT인터넷 :::' 카테고리의 다른 글
| MongoDB의 Document 사용하기 (CRUD) (0) | 2022.08.08 |
|---|---|
| MongoDB의 Database와 Collection 사용하기 (0) | 2022.08.04 |
| MongoDB의 Document 구조와 관계 패턴 (0) | 2022.07.28 |
| MongoDB 특징과 주요 개념 (125) | 2022.07.25 |
| Jupyter Notebook으로 AirFlow 사용하기 (0) | 2022.07.21 |