MongoDB의 구조와 주요 특징에 대해 정리한다.
Docker를 이용한 MongoDB 설정 방법은 아래 포스팅을 참고한다.
본 포스팅은 MongoDB 공식 문서와 아래 문서를 참고하여 작성했다.
정말 깔끔하게 정리가 잘 되어 있으므로 해당 포스팅을 읽어볼 것을 권한다.
MongoDB의 공식 문서는 아래 사이트를 참고한다.
주요 개념 (RDBMS와 차이)
MongoDB는 NoSQL (Not only SQL)로 기존 RDBMS와 다른 개념이 등장한다.
RDBMS 용어와 비교
MongoDB는 NoSQL 계열 데이터베이스로 Oracle, PostgreSQL과 같은 기존 RDBMS와 사용하는 용어가 일부 다르다.
|
RDBMS
|
MongoDB
|
|
Database
|
Database
|
|
Table
|
Collection
|
|
Tuple / Row
|
Document
|
|
Column
|
Key / Field
|
|
Table Join
|
Embedded Documents
|
|
Primary Key
|
Primary Key (_id)
|
참고로 MongoDB는 Join 연산을 지원하지 않는다.
따라서 Embedded Document는 Join이 아니고, Join과 유사한 결과를 얻기 위한 패턴을 의미한다.
Document
기존 RDBMS는 Row 단위의 레코드 기반이라면, MongoDB는 Document 기반의 데이터베이스이다.
위의 표에서 언급했듯이 Document는 RDMBS의 Row를 의미한다.
MongoDB는 Key-Value 기반으로 데이터를 관리하며, 입출력에는 JSON, 저장에는 BSON (Binary JSON)을 사용한다.
이러한 점으로 인해 MongoDB는 NoSQL에서 지향하는 Schemaless에 부합한다.
JSON과 BSON 포맷을 사용하므로 배열 형태 또는 계층적(Nested) 구조의 데이터를 쉽게 다룰 수 있다.
ObjectID
각각의 Document에는 _id라는 ObjectID 타입의 값을 가진다.

ObjectId는 RDBMS의 Primary Key와 동일한 개념으로 유일함을 보장하는 12 byte binary data다.
Primary Key는 사용자가 테이블을 생성할 때 지정해주면 RDBMS 서버에서 생성한다.
MongoDB는 분산 환경 지원을 위해 Sharding을 하기 때문에 서버가 아닌 클라이언트에서 생성한다.
-
4 Bytes - Unix Timestamp
-
5 Bytes - Random Value (MAC or IP 주소 3바이트 + Process ID 2바이트)
-
3 Bytes - 임의 값을 시작으로 증가하는 카우터
ObjectId에 대한 자세한 내용과 ObjectID가 중복된 값을 생성할 가능성에 대해서는 아래 문서를 참고한다.
Sharding
MongoDB는 대용량 데이터를 분산 처리할 수 있고 scale-out이 편리하다.
Sharding은 여러 장비에 걸쳐 데이터를 분할하는 과정을 의미하고 Partioning으로 표현하기도 한다.
mongos라는 MongoDB의 라우터 (Router)는 ObjectID로 데이터가 존재하는 Shard에만 데이터를 요청한다.
그림으로 표현하면 다음과 같다.
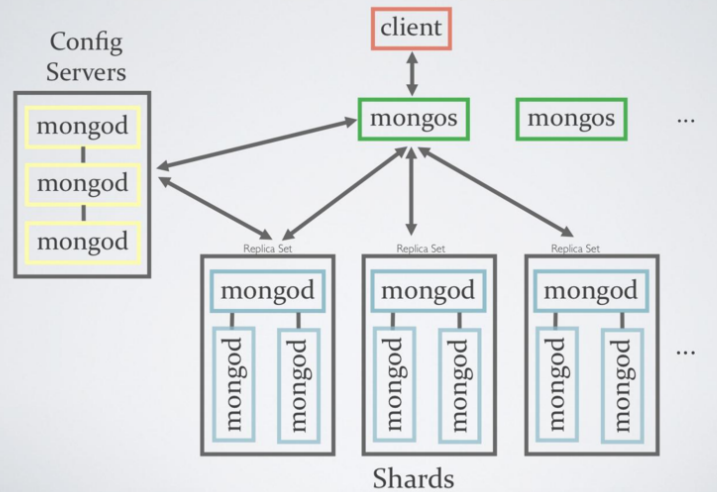
다음과 같은 장점이 있다.
-
여러 개의 노드 (클러스터)들을 단일 장비로 표현 가능
-
트래픽 부하의 분산 효과
-
병렬 작업을 통한 빠른 처리 성능
분산 환경이므로 가용성을 유지하기 위해 Primary와 Secondary로 구분되는 ReplicaSet을 가진다.
Primary에 장애가 발생하거나 사용이 불가능해지면, 과반수 투표를 통해 새로운 Primary를 선출한다.

기본적으로 3개의 ReplicaSet을 유지하지만, 소규모 환경에서는 2개로 운영 가능하다.
대신 Primary 선출 투표에만 참여하는 Arbitor라는 특수 멤버를 포함한다.

BASE
BASE는 Basically Available, Soft state, Eventually consistent의 약자로 ACID 보다 가용성을 우선시하는 개념이다.
완전히 상반된 개념은 아니고 가용성을 위해 일관성을 어느 정도 포기했다고 이해하는 것이 좋다.
각 단어들의 의미는 다음과 같다.
|
구분
|
내용
|
|
Basically Available
|
기본적으로 언제든지 사용할 수 있다
|
|
Soft state
|
외부의 개입이 없어도 정보가 변경될 수 있다
|
|
Eventually consistent
|
일정 시간이 지나면 동일한 상태가 되어야 한다
|
분산 환경에서 모든 노드 (Shard)가 완벽하게 동일한 상태를 유지하기 어렵다는 점을 고려하면 어느 정도 타당해 보인다.
해당 내용은 CAP (Consistency, Availibity, Partition tolerance) 이론에 의한 것으로 자세한 내용은 아래 포스팅을 참고한다.
Join 불가능
앞에서 언급했지만 MongoDB는 Join이 불가능하므로, Join이 필요 없는 데이터 설계가 중요하다.
Aggregation 연산을 활용해서 Join과 같은 결과를 만들 수는 있다.
그러나 참조하는 Collection이 많아지면서 성능이 느려지기 때문에 권장사항은 아니다.
Join 연산을 대체하는 방법 중 하나는 아래 그림과 같이 Embedded sub-document를 활용하는 것이다.

Embedded sub-document를 사용하는 방법으로 자세한 내용은 Extended Reference 부분을 참고한다.
메모리 의존적
MongoDB는 메모리 맵 형태의 파일엔진 데이터베이스이기 때문에 메모리에 의존적이다.
메모리의 크기가 전체 성능을 결정한다.
메모리 크기를 초과하면 하드디스크의 가상 메모리와의 Page Fault로 인한 빈번한 IO로 성능이 저하된다.

만약 데이터의 구조가 너무 크거나 복잡하다면 성능 저하가 발생할 가능성이 있다.
Document의 최대 크기는 16 MByte이며, 초과할 경우 Collection을 분리해서 관리해야 한다.
이러한 경우 Join이 필요 없는 정도로 Collection이나 Document를 분할하여 별도로 처리하는 것이 좋다.
'::: IT인터넷 :::' 카테고리의 다른 글
| MongoDB의 데이터 모델링 패턴 (0) | 2022.08.01 |
|---|---|
| MongoDB의 Document 구조와 관계 패턴 (0) | 2022.07.28 |
| Jupyter Notebook으로 AirFlow 사용하기 (0) | 2022.07.21 |
| AirFlow DAG 패키지를 AirFlow에서 사용하기 (0) | 2022.07.18 |
| AirFlow의 DAG을 파이썬 패키지로 구성하기 (4) (0) | 2022.07.14 |