1. 소개
1.1. 개요
TheHive는 침해사고 대응을 위한 플랫폼(Security Incident Response Platform)으로 오픈소스이다.
침해사고 뿐 아니라 캠페인이나 공격조직 분석과 대응에도 활용 가능하다.
- 외부 지표 수집과 분석을 위한 Cortex 엔진이 내장 되어 있다
- 분산 클러스터를 지원하여 스케일 아웃도 원활할 것으로 예상된다.
3.x 버전은 Elastic Search 기반이고, 4.x 버전부터 Cassandra와 Hadoop 기반으로 변경되었다.
공식사이트와 다운로드는 아래 내용을 확인한다. (더보기 클릭)
공식 사이트
TheHive Project
Scalable, Open Source Security Incident Response Solutions designed for SOCs & CERTs to collaborate, elaborate, analyze and get their job done
thehive-project.org
GitHub
TheHive-Project/TheHive
TheHive: a Scalable, Open Source and Free Security Incident Response Platform - TheHive-Project/TheHive
github.com
Docker (공식)
TheHive-Project/Docker-Templates
Docker configurations for TheHive, Cortex and 3rd party tools - TheHive-Project/Docker-Templates
github.com
Docker (커스텀)
RtKelleher/blog-resources
Contribute to RtKelleher/blog-resources development by creating an account on GitHub.
github.com
참고 Blog (Docker 셋팅)
Installing The Hive via Docker
👋 Hello again, today we will be continuing our adventure with the excellent S.O.A.R solution, The Hive. Today's post is all about initial…
nonsec.medium.com
참고로 4.x 버전 Docker 이미지는 Hadoop 대신 파일 기반 로컬 서버를 활용한다.
라이선스는 AGPL 3.0 (GNU Affero GPL) 이며, 네트워크로 연결 된 경우 사용자에게 소스코드를 공개해야 한다.
소스코드 공개가 제한 되는 경우 외부에 공개하지 않고 내부에서 사용하는 것을 권장한다.
- 조직 외부 사용자가 직접 접속하여 서비스를 사용하는 경우 코드 공개 필요
- 내부에서 사용하고 통신하는 대상이 내부 인프라인 경우 코드 공개 대상 아님
- 즉 외부에 상용/무료 공개 및 직접 접근 가능 여부가 핵심
1.2. 특징
기본적인 특징은 다음과 같다.
- MISP 인스턴스와 동기화를 통한 MISP 이벤트 분석
- 협업을 위한 동시 작업 기능 제공 (악성코드 분석, 이벤트 추적 등)
- 침해사고, 외부 이슈, 이벤트 조사와 대응 가능
- 조사 단위와 Observable (지표 단위)에 대한 TLP 적용 가능
- 각종 조사 단위 생성과 병합 가능 (업무 단위는 Case - Task - Job 순으로 구성)
- MISP도 외부 지표 수집 가능하지만 Cortex를 이용한 자체 수집 가능
- MISP와 거의 완벽한 호환을 자랑하지만 MISP가 없어도 됨
참고로 MISP는 이전 발행글인 아래 포스팅을 참고한다.
MISP (Malware Information Sharing Platform)
1. 소개 1.1. 개요 MISP는 악성코드 기반의 위협 데이터를 관리하는 악성코드 첩보 공유 플랫폼(Malware Information Sharing Platform)으로 오픈소스이다. 보안관제나 CERT, 또는 정보보안 부서에서 많이 활용
www.bearpooh.com
3.x 버전까지는 ElasticSearch가 주저장소였으나 4.x 버전부터 Cassandra와 Hadoop으로 변경되었다.
- ES의 너무 급격한 버전 올림이 가장 큰 원인인 것 같다. (ES 강의에서도 강사들이 버전이 너무 빨리 바뀐다는 하소연을 한다.)
- ElasticSearch는 인덱스 서버로만 활용
- Cassandra와 Hadoop은 프로덕션 (실서비스) 환경에 대한 것이고, Docker는 파일 기반 로컬 서버 사용
TheHive와 Cortex 내부 코드는 Scala 언어로 작성되어 있고, 웹 UI는 JavaScript 기반으로 되어 있는 것으로 파악된다.
- 내부 기능 커스터마이징은 생각보다 어려울 수 있다.
- 웹 UI 한글화도 어렵지 않을까 생각한다. (이 정도면 해당 오픈소스에 한국어 버전 커미터로 합류하는게 낫다)
- AMP와 연동할때 필요한 추가 필드가 있는 경우 개발 소요는 어느 정도 있을 것으로 판단된다.
여담으로 Scala 언어를 한번 맛보면 안 할 가능성이 매~~~~우 크다.
- 지난 3년간 데이터 엔지니어 업무를 수행하면서 Spark과 Twitter Server 코드를 다룰 일이 있었다.
- 함수형 언어 특성상 익숙해지는데 상당한 시간과 노력이 요구된다. (파이썬 같이 쉽고 빠르게 접근할 수 있는 언어는 아니다)
- 역설적으로 익숙해지면 상당히 깔끔하고 편리한 언어다.
- Java를 기초로 하여 개발 된 언어이다 보니 Java와 JVM에 대한 이해가 필요하다.
1.3. 예시
데이터 수집과 활용에 따라 다음과 같은 분석이 가능해진다. (출처 : https://github.com/TheHive-Project/TheHive)
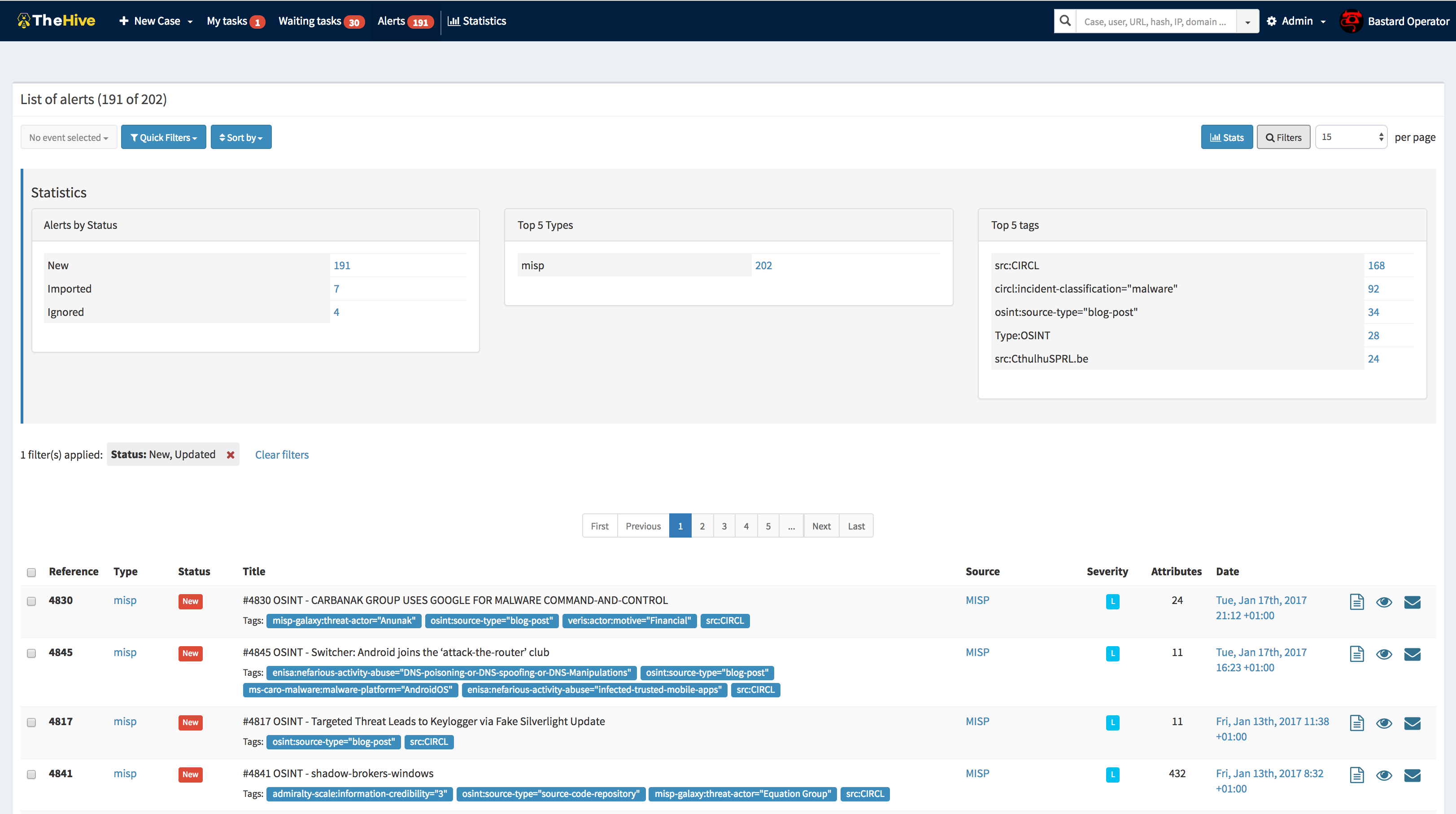
복잡하게 느껴질 수 있으나 Jira와 MISP가 합쳐진 시스템이라 보면 좋지 않을까 싶다.
TheHive는 Case - Task로 구성되어 있는데 Jira에서는 아래와 같이 대응 된다.
- Jira (애자일) : Epic - Story (or Task)
- Jira (일반업무) : Project - Task
참고로 Jira의 애자일에서 Epic은 해당 Project를 완수하기 위한 다수의 업무 단위이고, Epic은 개발 이슈인 Story와 부가 업무 (자료 조사, 테스트 등)인 Task로 구성된다.
또한 Jira의 일반 업무인 경우 해당 Works의 프로젝트가 Case, 각각의 개별 이슈가 Task로 대응된다.
각 Case에는 Observable과 TTPs가 있는데 조사 중 발견하거나 분석한 지표와 TTPs를 정리할 수 있다.
2. Docker 셋팅 방법
2.1 개요
Production 환경에서는 단계별로 셋팅하거나 Ensible을 활용한 셋팅이 필요하지만, 테스트와 기능 확인이 주 목적이므로 Docker를 이용한 셋팅을 진행한다.
실서비스가 목적이 아닌 테스트 목적이므로 보다 빠르고 쉬운 설정을 위해 아래 블로그의 방법을 참고한다.
별도의 Docker 이미지 빌드 과정이 필요하지 않으므로 빠른 환경 구성이 가능하다.
Blog (Docker 셋팅)
Installing The Hive via Docker
👋 Hello again, today we will be continuing our adventure with the excellent S.O.A.R solution, The Hive. Today's post is all about initial…
nonsec.medium.com
Docker (커스텀)
RtKelleher/blog-resources
Contribute to RtKelleher/blog-resources development by creating an account on GitHub.
github.com
해당 GitHub의 코드를 다운로드하고, TheHive\docker-compose.yml 파일을 다음과 같이 수정한다.
윈도우에서는 cortex의 tmp 공유 경로를 수정하지 않으면 오류가 발생한다.
dockercompose.yml
elasticsearch:
container_name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:7.12.0
# ... 생략
cortex:
image: thehiveproject/cortex:latest
container_name: cortex
restart: unless-stopped
depends_on:
- elasticsearch
environment:
- JOB_DIRECTORY=/opt/cortex/jobs
ports:
- "0.0.0.0:9001:9001"
volumes:
- ./cortex/application.conf:/etc/cortex/application.conf
- /opt/cortex/jobs:/opt/cortex/jobs
- /var/run/docker.sock:/var/run/docker.sock
- ./cortex/log/:/var/log/cortex
- tmp:/tmp # ./cortex/tmp:tmp로 수정
# 윈도우에서 cortex의 tmp 공유 경로를 수정하지 않으면 오류가 발생한다.
command: '--no-config --no-config-secret'
networks:
- Hive
thehive:
image: thehiveproject/thehive4:latest
# ... 생략
이후 docker-compose up을 하면 정상적으로 설정이 진행된다. 약 2~3분간 기다려야 한다.
2.2 Cortex 설정
실행이 완료되면 웹 브라우저를 실행하고 http://localhost:9001로 접속하여 Cortex의 설정을 변경한다.
최초 접속하면 DataBase를 Update해야 한다.
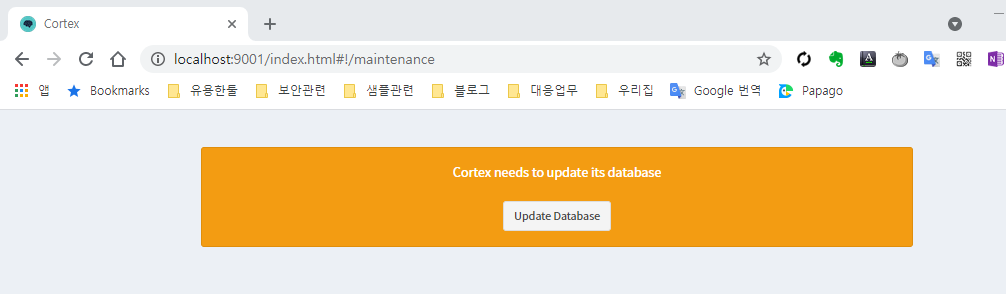
Update Database 버튼을 클릭하면 관리자 계정 생성 화면이 나온다. 임시로 admin / admin으로 지정한다. 향후 실서비스는 다르게 지정해야 한다.

생성한 아이디와 비밀번호를 이용하여 로그인 한다.
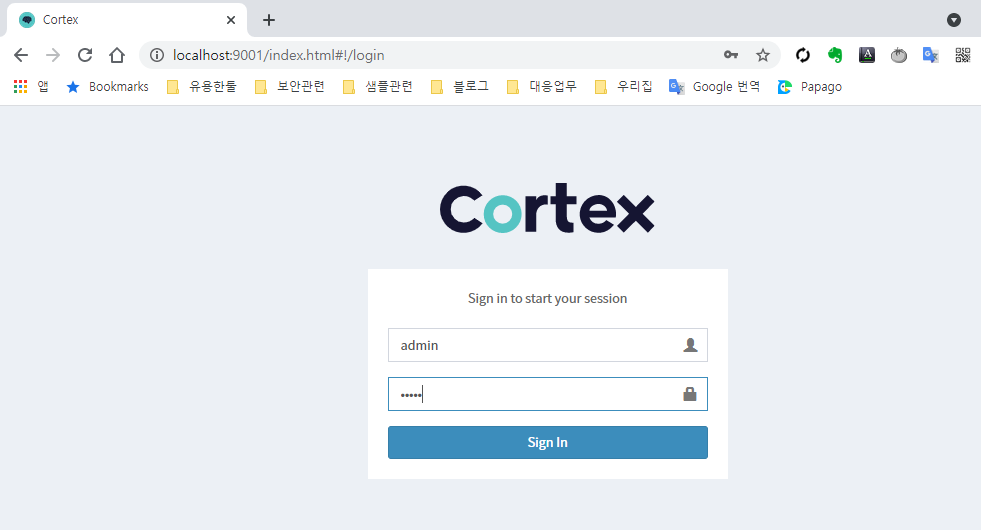
화면 중앙 active 옆의 cortex를 클릭한다.
Create API Key 버튼을 클릭한다.

Reveal 버튼을 클릭하면 생성 된 API Key를 확인할 수 있다.

2.3 TheHive 설정
TheHive\thehive\application.conf 파일을 열고 아래 부분의 API Key 항목에 입력한다.
application.conf
play.modules.enabled += org.thp.thehive.connector.cortex.CortexModule
cortex {
servers = [
{
name = local
url = "http://cortex:9001"
auth {
type = "bearer"
key = "api key" # 이 부분에 확인한 API Key를 입력한다.
}
}
]
# Check job update time intervalcortex
refreshDelay = 5 seconds
# Maximum number of successive errors before give up
maxRetryOnError = 3
# Check remote Cortex status time interval
statusCheckInterval = 30 seconds
}
해당 파일을 저장하고 실행 중인 Docker 컨테이너들을 종료하고 다시 시작한다. 화면에서 Ctrl + C를 누르면 Gracefully stopping을 진행한다. (서비스 종료 후 컨테이너 종료)
컨테이너가 다시 실행 되면 http://localhost:9000으로 접속한다. 최초 로그인 계정은 admin@thehive.local / secret이다.
테스트는 그대로 사용해도 무방하나 실서비스는 별도의 관리자 계정을 생성하고, 임시 계정을 비활성화 하거나 삭제해야 한다.

실행하면 상단 메뉴가 아무것도 없는데 정상이다. 관리자 계정은 조직과 계정 관리, 기본 설정만 담당한다.

New Organisation 버튼을 눌러서 새로운 조직을 생성한다. (여기서는 test)

생성한 조직을 클릭하고 Create new user를 눌러서 새로운 사용자를 추가한다. (여기서는 test@test.com)
- 권한은 3가지가 있는데 org-admin, read-only, analyst이다. (추가 및 변경은 Admin → Profile에서 가능하다)
- 보통 분석조직(또는 파트) 리더는 org-admin, 조직원(파트원)은 analyst, 그 외 사용자는 read-only로 설정한다. (필요에 따라 적절히 권한 분배)
- 생성하고 나면 password와 api key 확인 메뉴가 존재한다. (cortex와 사용법은 동일하다)
- 해당 API Key는 내부 수집 기능이나 확장 기능의 사용자 인증 목적으로 사용하는 것으로 보인다.
반드시 New password를 클릭하고 초기 비밀번호를 설정해야 한다.

상단의 Admin 버튼을 누르면 설정 메뉴가 출력된다.
Analyzer templates, Taxonomies, MITRE ATT&CK pattern은 클릭해서 안내에 따라 기본 제공해주는 데이터를 다운로드하고 Import한다.
Analyzer templates은 상당수의 OSINT와 보안 벤더의 보고서 템플릿을 활용할 수 있다. 물론 MISP, YETI, CuckooSandbox 템플릿도 존재한다.
Taxonomies는 MISP에서 제공하는 최신의 Official 목록을 적용할 수 있다.

MITRE ATT&CK pattern은 IMPORT하면 시간이 오래 걸린다. 대신 Import가 완료되면 아래와 같이 MITRE ATT&CK Tatic과 Technique들을 확인할 수 있다.

이제 로그아웃을 하고 생성한 사용자로 접속하면 실제 기능을 사용할 수 있다.
3. 기능 분석
3.1. 초기 화면
생성한 계정으로 접속하면 다음과 같은 화면이 출력된다.

- Case는 전체 분류로 Jira의 프로젝트 또는 조사 단위로 보면 좋다.
특정 침해 사고를 지정할 수도 있고, 외부 보고서 관련 대응을 지정할 수도 있다. - Task는 해당 Case를 완수하기 위한 개별 작업 단위를 의미한다.
Case가 침해사고 조사라면 Task는 관련 지표 분석, 동적 분석, 정적 분석 등 다양한 지정이 가능하다. - Task 내에 Log 항목이 있는데 Jira의 댓글을 생각하면 이해하기 쉽다.
- Task Sharing은 해당 Task를 공유할 조직이나 사용자를 지정할 수 있다.
Observable은 발견한 관련 지표를 입력할 수 있다.

TTPs는 ATT&CK 기반의 Tactic과 Technique, 그리고 Procedure를 입력할 수 있다.
- Tactic, Technique은 선택형이고, Procecdure는 자유입력이다.
- Procedure는 Markdown을 적용할 수 있다.

3.2. 기능 확인
Cortex에 Analyzer 추가하는 방법은 Github에 있는 매뉴얼을 따라하면 어느 정도 삽질이 필요하지만 설정 가능하다.
TheHive-Project/CortexDocs
Documentation of Cortex. Contribute to TheHive-Project/CortexDocs development by creating an account on GitHub.
github.com
단, 분석기에 사용하는 모듈들을 설치해야 하는데 Docker 이미지가 Debian 리눅스라서, 사내 저장소를 사용하는데 제한이 있어 정상 진행이 되지 않는다.
- 최초 셋팅은 어렵지만 이후 Cortex UI에서 설정하는 것은 어렵지 않음
- 일부는 샘플 분석 (정적 또는 동적)을 필요로 하는 경우도 있어서 망 구성시 주의 필요
Cortex에 Analyzer, Responser는 Python으로 작성되어 있어 커스터마이징 가능하고, 표준화 되지 않은 데이터 포맷을 가공해서 넣을 수 있는 분석기 작성도 가능할 것으로 보인다.
향후 Deep-dive한 기술조사와 실서비스에는 Ubuntu 기반으로 변경하고, 분석기를 활용해 보면 좋을 것으로 판단된다.
해당 테스트는 MISP 검토를 우선 마무리하고 진행 예정이다. (진행 일정 미정)
3.3. 클러스터 확장
4.x 버전의 클러스터 확장은 아래 문서를 참고한다.
https://github.com/TheHive-Project/TheHiveDocs/blob/master/TheHive4/Administration/Clustering.md
Cassandra와 Minio 지원하는데, 일부 자료에서는 Hadoop Filesystem도 지원하는 것으로 되어 있다.
클러스터 확장 기능을 지원하기 때문에 쿠버네티스에서도 Docker를 이용한 클러스터 구성이 가능할 것으로 예상된다.
Cortex 또는 MISP 데이터들은 Spark을 이용한 가공과 분석도 용이할 듯..
3.4. 기타
이제 무엇을 해야할지 막막하다면 당연하다. 오픈소스는 일반적으로 다음과 같은 공통 특징이 있다.
- UI/UX 완전 별로 (빠른 기능 파악은 거의 불가능)
- 매뉴얼 허접 (삽질 필요)
- 보안 오픈소스는 생각보다 자료가 많이 없음 (삽질 필요)
- 한글화는 진즉에 포기 (영어 공부 열심히)
매뉴얼은 다음 페이지를 참고한다. (w. 구글 번역)
TheHive-Project/TheHiveDocs
Documentation of TheHive. Contribute to TheHive-Project/TheHiveDocs development by creating an account on GitHub.
github.com
즉, 이제부터 삽질의 시간이다. 단기간에 정리 될 것은 아니므로, 천천히 매뉴얼을 참고하여 사용해보면서 주요 기능들을 정리한다.
4. 결론
전체적인 느낌은Jira와 MISP가 합쳐진 느낌으로, 각종 보안 이슈에 대한 조사 내역도 정리하기 좋게 되어 있다.
- 이슈 생성, 종료, 할당, 병합 등이 가능하다
- TTPs와 탐지 지표들을 연결할 수 있다
- 다양한 외부 소스와 연동 가능하다
대량 처리 기능이나 스케일아웃, 외부 지표 활용과 분석, 커밋과 릴리즈 주기를 고려할때 FIR보다는 훨씬 나은 것으로 보인다.
표준화 되지 않은 데이터와 내부 정보 통합을 위한 추가 개발이 필요할 것으로 판단된다.
다만 Scala 언어로 작성 된 만큼 기능 수정은 쉽지 않을 것으로 보이기 때문에, 해당 부분에 대한 해결 방안이 주요 이슈가 될 것으로 보인다.
'::: 정보보안 :::' 카테고리의 다른 글
| MISP 사용해보기 2 - Feed 추가와 데이터 다운로드 (0) | 2021.06.09 |
|---|---|
| MISP 사용해보기 1 - 기본 설정과 이벤트 추가 (0) | 2021.06.09 |
| YETI (Your Everyday Threat Intelligence) (0) | 2021.06.07 |
| CRITs (Collaborative Reseach Into Threats) (0) | 2021.06.07 |
| MISP (Malware Information Sharing Platform) (0) | 2021.06.05 |